【大模型】漏洞检测修复方向
Examining Zero-Shot Vulnerability Repair with Large Language Models(SP 23‘)
论文方向:
专注于研究软件源码漏洞的大模型修补方案生成,侧重于零样本有效修补方案的生成。文章提出的研究问题为:
RQ1 现成llm是否能生成安全的补丁修复漏洞?
RQ2 改变prompt中注释的上下文数量是否影响LLM提出修复意见的能力?
RQ3 现实世界应用时存在什么挑战?
RQ4 llm在修复漏洞方向有多可靠?
论文主要工作
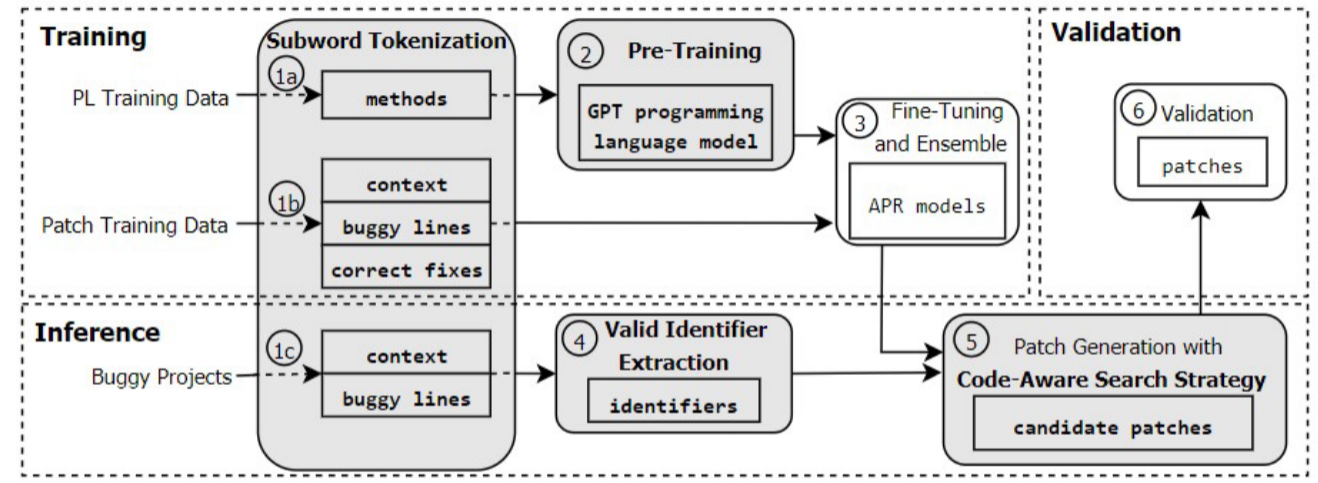
针对RQ1、2
漏洞程序代码生成:
指定两种类型的漏洞(CWE787写出边界和CWE89SQL注入),给大模型(Codex)提供相关的短程序,让大模型补全,再通过单元测试和CodeQL运行,评估程序功能。
生成过程中作者设置了不同温度值{0 0.25 0.5 0.75 1}为每种codex引擎生成10各程序。
漏洞修复
针对以上两种漏洞类型,作者将原始提示词中添加CodeQL识别出的错误代码,将CodeQL的所有信息作为注释,并注释掉漏洞代码,重点关注top_p和temperature两个参数,另LLM重新生成修复后的代码。结果是,CWE787的22034个有效程序中有2.2%被修复,CWE89有29.6%被修复。结论是,不同的漏洞类型修复效果与数据集强关联,但也没有哪个确定的研究参数可以完全覆盖所有修复场景。
- 提示词工程和手工写漏洞样本
本实验针对RQ2,首先扩大了提示词应用的范围,然后手工编写了一些含有漏洞的代码样本。这些样本总结如下:
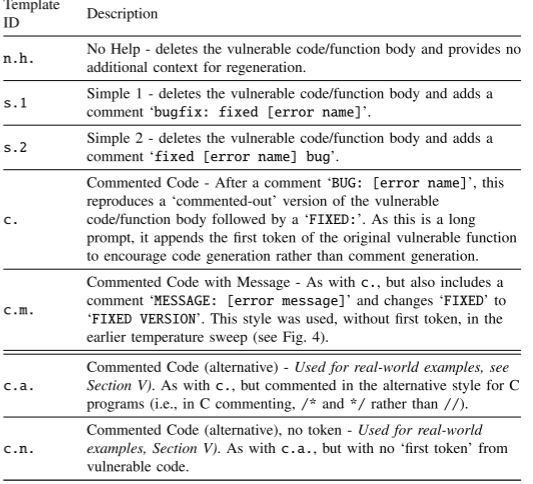
作者设计了5个提示词模板,主要区别在于改变了提供给LLM上下文的数量,包括措辞和词序的变化。如下:
结果是,提示词模板在不同漏洞类型、场景和LLM差距都很大,很难得出定论。
- 修复硬件漏洞样本
作者同样关注了硬件漏洞修复场景,这些场景都基于CWE1271(寄存器复位时未初始化)和CWE1234(允许覆盖所)。作者改编了MITRE的示例代码,将源文件进行函数和安全测试,再用之前提到的提示词组合进行实验,结果是,提示词上下文较少时,LLM表现更好。
针对RQ3
对于真实场景下,完整的上下文不再能提供。这是主要挑战。
- 数据集:ExtractFix
选取样本的原则包括:漏洞是否能被定位到文件;是否可以找到出发漏洞的概念验证输入;是否存在测试组件。
- 源码修减和建议整合
为了解决大模型的token数量限制,对输入的prompt进行整合,将一些源码信息也加入其中
Out of sight, out of mind: Better automatic vulnerability repair by broadening input ranges and sources(ICSE 24‘)
论文方向
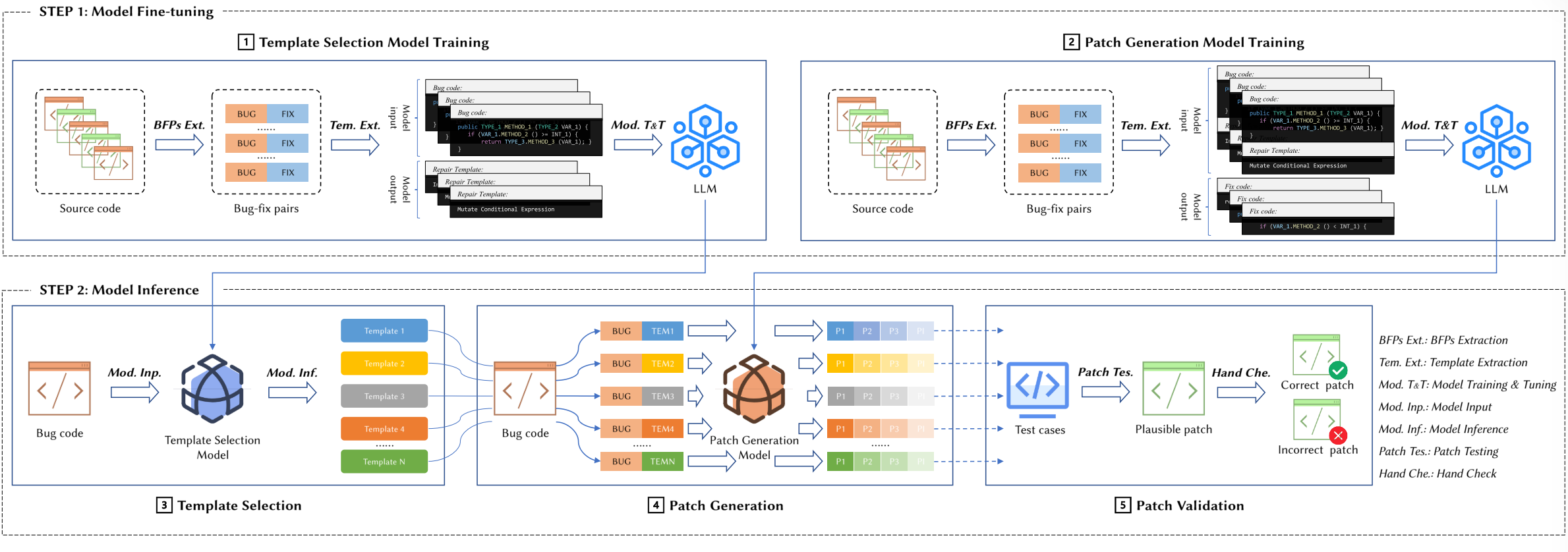
针对现有问题:1.源码序列输入长度被限制;2.扩展模型输入信息类型(aST);3.广泛利用专家知识(CWE)。提出了VulMaster处理整个漏洞代码生成修复程序。
论文主要工作
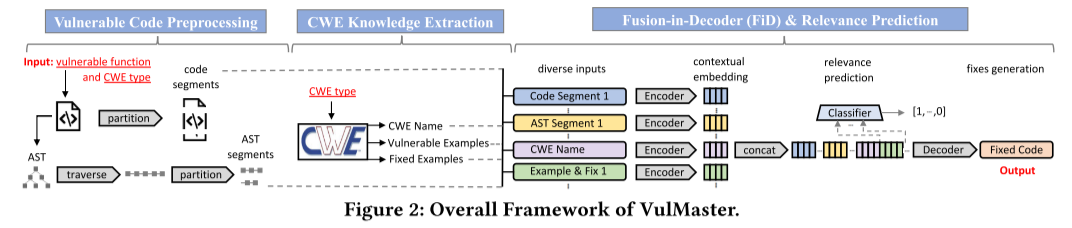
上图前两个阶段均为构造输入信息的步骤,第三个阶段负责编码和生成修复。
源码预处理
使用CodeT5tokenize源代码
分段,保证每个段不超过transformer序列要求的token长度512
转换AST,并将AST转换为节点序列
CWE知识抽取
.PNG)
- 构建字典,键为CWE类型,值为对应的信息(CWE名称、漏洞示例和ChatGPT生成的修复示例)
FiD(Fusion-in-Decoder)和相关性预测
AST的主干预测模型。在CodeT5预训练过程中不包括AST节点序列,这种结构将缺乏表现力。作者的改进策略为补上这个预训练阶段,用漏洞修复语料库补充。
上下文嵌入。上下文嵌入作为编码器(CodeT5)的输入
相关性预测。并非所有CWE信息库的修复代码与漏洞都有相关性,与输入CWE类型相关联的对被认为是最相关的,而与输入CWE类型的父/子/兄弟CWE类型相关联的对被认为是不太相关的。
FiD。将所有上下文信息拼接在一起作为encoder的输入
多任务学习。相关性预测+漏洞修复
实验
数据集:真实数据集(VulRepair+Vrepair),由8482对漏洞C函数组成,包含漏洞数据和修复数据。
评估指标:精确匹配(Exact Match),指生成代码中与groundtruth具有相同token序列的百分比;BLEU-4分数,指的是生成代码与groundtruth之间的token级别相似性;CodeBLEU分数,一个BLEU变体,额外考虑代码结构,再计算指标时考虑Top1预测原则。
实验结果
VulMaster在所有基线中取得了最好的结果,并且在很大程度上优于SOTA。此外,像GPT-3.5和GPT-4这样的llm很难有效地修复现实世界的软件漏洞,可能是因为它们无法更新参数以充分利用训练数据。Sun等人也报道了代码总结中的类似现象,在BLEU得分方面,GPT-3.5的表现明显低于经过微调的预训练的CodeT5。
.PNG)
- VulMaster核心影响是什么
消融证明本方法各组件的重要性。
- 研究不同分段数量对结果的影响
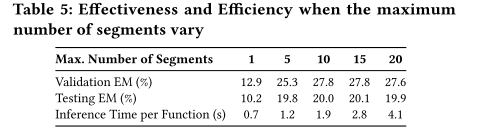
Vision Transformer Inspired Automated Vulnerability Repair(ACM Transactions on Software Engineering and Methodology, 2024)
论文方向:
针对性地提出一种可以关注漏洞代码区域的编码器-解码器结构的漏洞修复框架,提出了一种漏洞掩码(VM)来使得解码器的交叉关注机制,可以强调生成过程中对漏洞区域的关注。
问题定义:
主要关注函数级的修复。通过增删改与编码器输出的源码token生成对应的修补token,修改内容将用特殊的标记包围起来
主要方法:
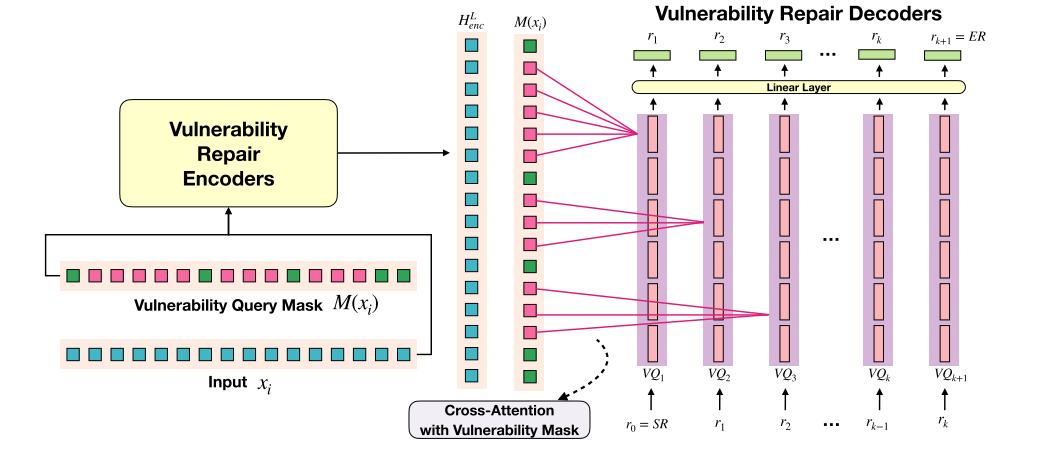
输入token xi以及VM(漏洞掩码)为编码器的输入,然后编码器输出嵌入,在解码器中,每个VQ从之前的修复tokenr初始化,再由多个解码器层转发,通过线性层生成下一个修复token r。每个伽玛琪中,利用VQM交叉关注来强调漏洞部位,交叉匹配vq和嵌入。
VM是一个分布概率,代表某个token是漏洞token的可能性。
实验
数据集:使用和4一样的数据集,包含来自BigVul、CVEfixes的C语言漏洞修复语料库数据。
模型训练:在文献4提供的缺陷数据(bug修复)上预训练。
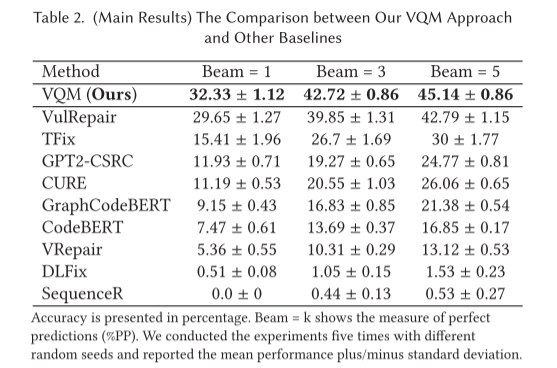
实验结果
- 对比实验,如果生成的内容和人为编写的修复内容完全相同则认为是完美预测,%PP就是计算完美预测的占比。
Neural Transfer Learning for Repairing Security Vulnerabilities in C Code(IEEE Transactions on Software Engineering 23)
论文方向
以迁移学习的思路,从大量错误修复语料库中预训练,再用小量级的漏洞修复数据集(BigVul+CVEfixes)上微调。该方法被称为VRepair
方法
源域训练:收集开源代码平台的bug提交收集大量的修复样本,这些数据不针对漏洞修复,但是可以作为迁移学习的基础样本集。
目标域训练:采取高质量的漏洞修复数据集。漏洞修复数据集稀缺,在上一步训练的基础上进一步调整Vrepair的权重。在训练开始前,在源码序列前添加CWE相关标记
推理:根据给定的漏洞定位技术预测先前未知的漏洞修复。对于每个潜在的漏洞区域,Vrepair输出多个预测,这些预测则转换为多个源码补丁。
实验
数据集:【bug修复数据集】从github中按照关键词bug或vulnerable搜索C代码的提交,最终经过过滤后获取1838740个函数集的提交记录,去重后有655741个;【漏洞修复数据集】基于Big-Vul和CVEfixes进行微调,获取CVE编号后在git爬取修复链接,包含1754个项目中的5365个漏洞类型,被分类为180个CWEid
RQ1:只进行源域训练或者目标域训练会怎么样?
RQ2:源域和目标域训练的迁移学习在漏洞修复任务的准确率?
RQ3:与去噪预训练相比,迁移缺席表现如何
RQ4:不同的数据分割策略如何影响模型性能?
实验结果
- RQ1
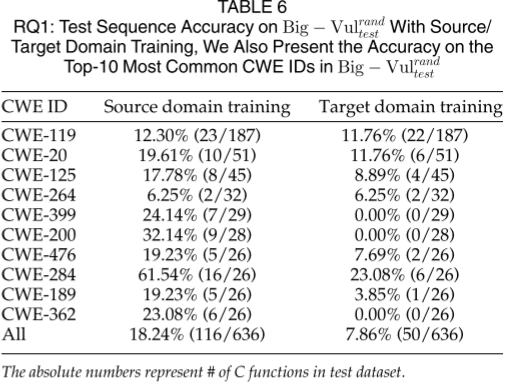
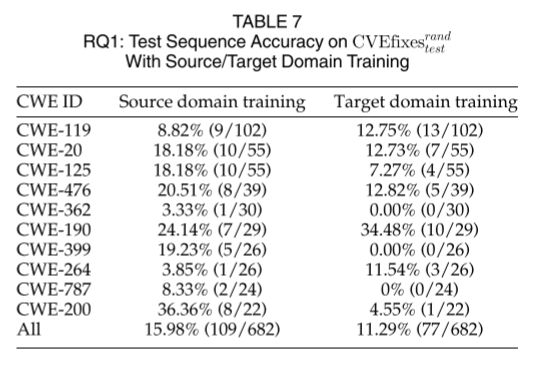
- RQ2
目标域训练的模型应用于源域训练的最佳模型上,以衡量其性能,结果证明,bug修复和漏洞修复两个任务具有相似性,可以进行迁移
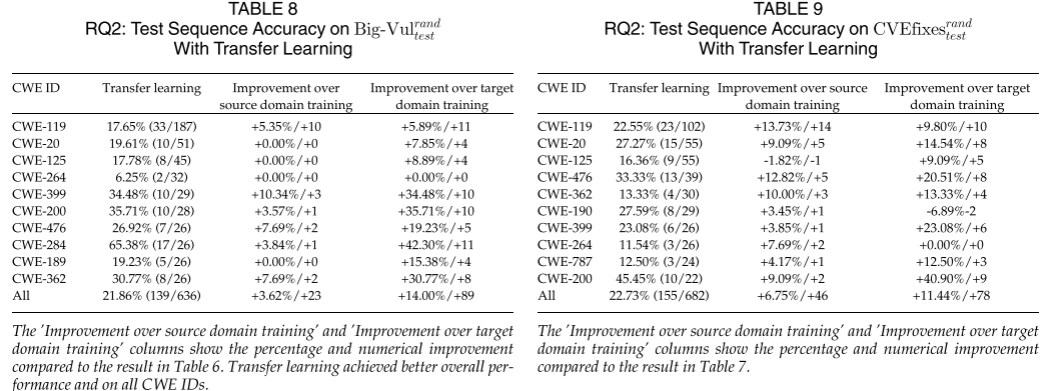
- RQ3
迁移学习在大小相似的数据集上由于去噪预训练,尤其是源域的bug修复任务
- RQ4
对于考虑的两种数据分割策略(随机和基于时间的),迁移学习获得了更稳定的准确率
Seqtrans: automatic vulnerability fix via sequence to sequence learning(IEEE Transactions on Software Engineering 23)
论文方向
APR(Automatic Program Repair)严重依赖于特定领域知识或者预定义的模板,就是说需要通过小的漏洞数据集中进行训练学习,需要大量特征且不够准确。
方法
类似于上一篇,也是在大范围bug修复提交上面进行预训练,再使用漏洞修复数据集微调。
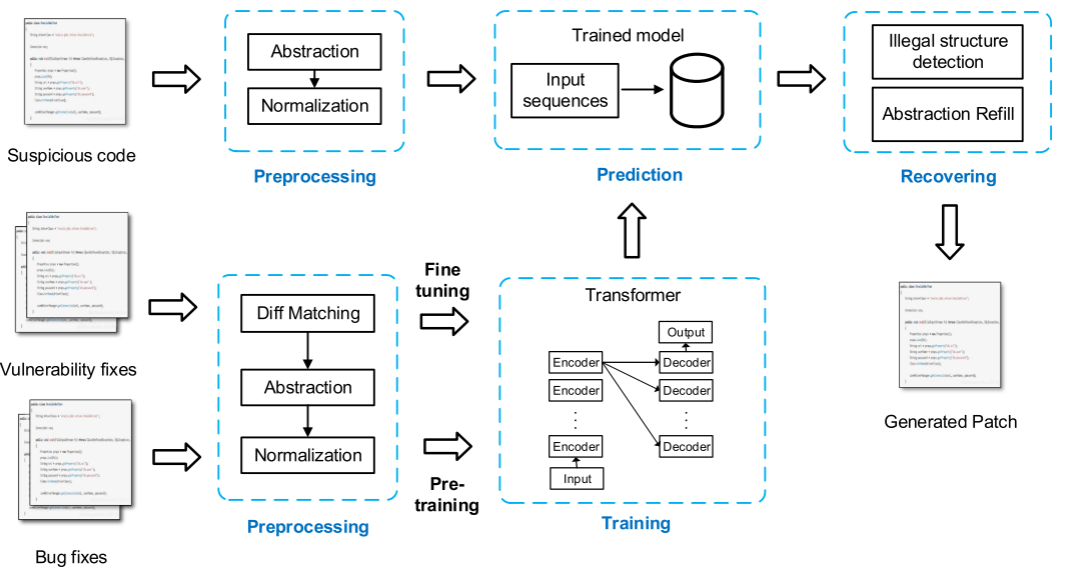
- 预处理:从两个数据集中提取上下文(分别是bug修复和漏洞修复),基于数据依赖关系进行规范化,提取自定义的使用链。
NAVRepair: Node-Type Aware C/C++ Code Vulnerability Repair(Preprint)
论文方向
结合代码AST和错误类型作为输入,同时提出的修复框架独立于LLM模型,这样可以保证模型的泛化性以及在C++这样的底层语言上的性能。
方法:
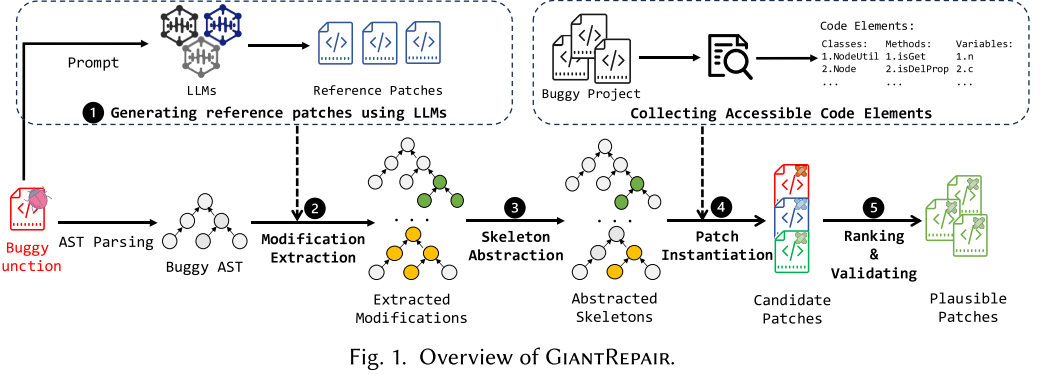
总结该框架:通过定位AST中修复代码的根节点获取与缺陷相关语义的上下文信息,并将这一部分与节点相关的CVE信息作为提示信息一起交给大模型进行补丁生成。
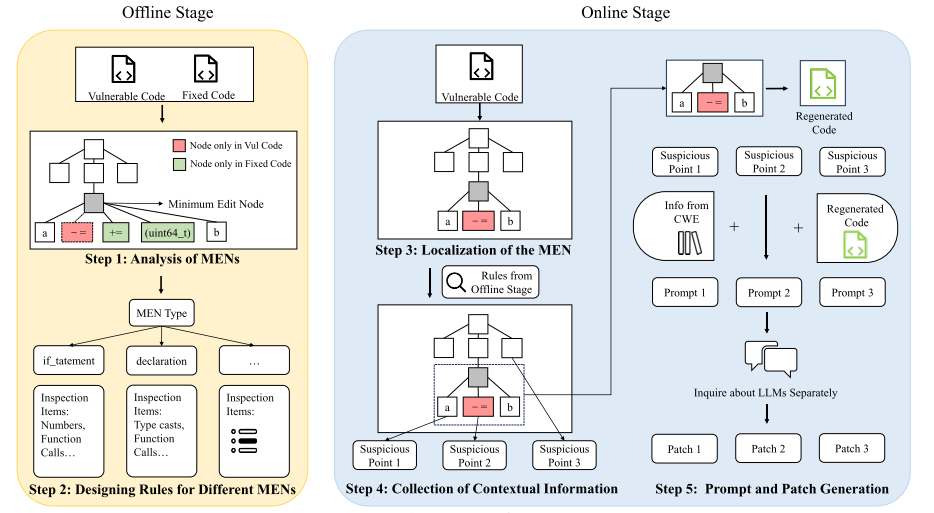
- 离线阶段:给定C代码补丁,将漏洞代码和修复后的代码作为输入,首先定位最小编辑节点(MEN),根据它的类型设计规则来收集上下文信息。
MEN是所有被修改节点的根节点,旨在区分内部语境和外部语境,在修复过程中只有小部分会被修改,通过这种根节点,我们就可以聚焦于需要修复代码的核心。
- 在线阶段:该阶段输入只包含可能存在漏洞的代码,与漏洞类型结合,提供大模型以提示词,借由此生成漏洞修复补丁。给定可疑代码,定位其MEN,再根据里现阶段得出的规则,通过删除不相关的信息简化源码,最后将这一部分和提示信息提供给LLM生成补丁。
实验
数据集
CVEFixes,包含C(C++)漏洞以及CWEid,来源为真实场景。本文的实验关注2023年排名前25的CEW。数据处理掉所有注释,收集每一对漏洞代码和修复后的代码。
基线大模型
ChapGPT(3.5)DeepSeek Coder(33B)Magicoder(6.7B)
评价标准
CodeBLEU:生成代码与原代码匹配的程度
TED(树编辑距离):将一个树转为另一个树所需要的最小操作数,量化两个树的相似性
PP(完美预测比例)
实验结果
对比
在大模型之间采用或不采用本文框架
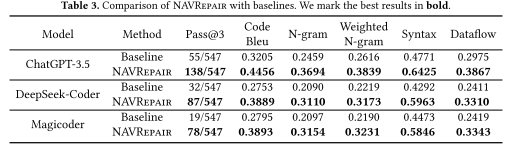
不同类型的AST类型影响
MEN涉及for循环时,修复效率最好
超参数影响
NAVRepair的性能不太依赖于超参数
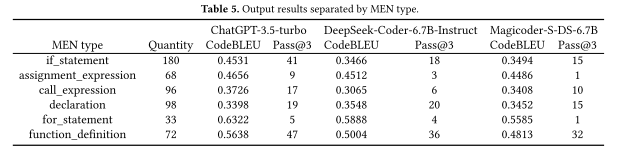
AIBugHunter: A Practical tool for predicting, classifying and repairing software vulnerabilities(Empirical Software Engineering, 2024)
论文方向
提出了AIBughunter,一种可以集成在IDE的实时漏洞检测、解释和修复的工具,基于多目标优化(MOO)以及Transformer架构。
论文方法
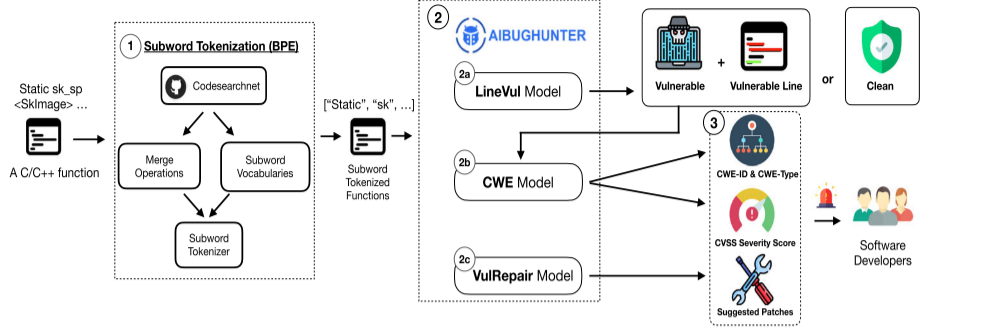
Directional Diffusion-Style Code Editing Pre-training (Preprint)
论文方向:
基于扩散原理进行代码生成:现有模型通常直接处理代码编辑前后的差异,而忽略了代码在真实开发过程中是逐步修改的;现有方法多基于行级差异(如diff工具的输出),难以捕捉细粒度的令牌级编辑;现有模型在生成代码时未充分考虑代码编辑的上下文信息,导致生成的代码可能与实际需求不符;现有去噪方法引入的噪声与开发者实际编写的代码存在较大差异,难以模拟真实编辑场景。
方法:
方向性扩散(Directional Diffusion)
扩散模型,模拟开发者逐步修改代码的过程:从旧代码XT开始,以掩蔽策略引入人工噪声(XT+1)引导扩散方向,中间状态Xt代表进化噪声,强化编辑方向,图示中下方的示例模拟人工编辑时对代码内容的修改,绿色表示新增,蓝色表示修改。最终的变化包含引入新的patch p2,新增变量v3 f12 以及更改变量f11 f21.
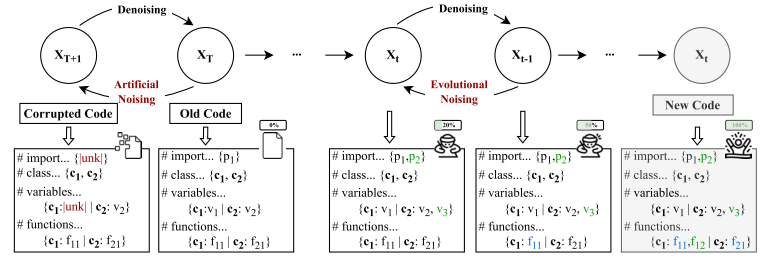
模型架构
基于CodeT5的编解码器结构,采用自回归生成方式,联合多任务学习。
- 代码演进中增量修改:
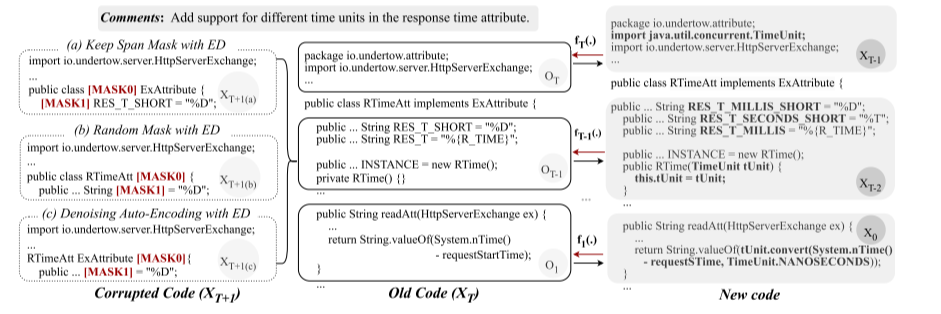
该图是一个真实例子,若想要达成Comments标注的目标,需要几步:1.引入恰当的包;2.重新定义变量;3.实现函数体。这种增量编辑过程与扩散原理的逐步去噪吻合,每一次修改都可以视作对旧代码的去噪。模拟一个动态迭代过程,可以导向代码修复的过程来跟踪和预测代码的改进路径。
- 代码演进中增量修改:
现有用于离散文本生成的扩散模型通常通过连续高维嵌入级别的多步去噪过程来学习文本依赖关系,然后通过舍入过程将这些嵌入映射到自然语言文本。然而,与自然语言相比,代码具有更强的句法结构和语义关系。专为离散数据(如代码)设计的DivoT5采用离散数据级扩散,其中每个噪声代表特定的代码变化,反映代码的自然演变。在降噪阶段,我们首先在旧代码中引入人工噪声,学习符号级代码的编辑过程,丰富旧代码的上下文。然后,我们将编辑的中间进化过程作为一种特殊的进化噪声来处理,以增强代码进化的方向性。
When Large Language Models Confront Repository-Level Automatic Program Repair: How Well They Done?(ICSE 24’)
论文方向:
面向传统自动程序修复(APR)仅面向单个函数或单个文件的局限性,提出一种新的基准RepoBugs面向存储库级别的漏洞修复。同时,为了解决大语言模型的token限制,并且初步方法提供的存储库级别的上下文往往是冗余的,本文还提出了对应的解决办法(Repository-level context extraction,RLCE)来提供精确的上下文关注。
论文方法(RLCE):
RLCE是一个静态的上下文检索工具,目标是根据代码库的结构自动将其解析为代码片段。上图将本方法分为两步:
(1)解析存储库文件并且构造项目结构树:
结构树重点关注五种节点:目录、文件、类、函数、全局变量。节点之间的连接遵循存储库中的原始结构关系,文件实体的子节点包括全局定义的变量、类和函数。项目结构树的叶节点仅限于函数节点或变量节点。
(2)根据错误位置在项目构造树中检索,获得对应代码段:
目标代码修复任务的错误定位在一行或几行代码中,称为“错误位置”。在检索之前,上下文检索工具需要分析和提取在错误位置中调用的函数和全局变量,我们称之为错误调用函数(error - invocation functions, EIF),下面定义几种上下文:
EIF:检索包含存储库范围内提取的错误调用函数的定义的代码段;
EIF的调用者:在存储库中搜索错误调用函数的其他出现(不包括错误位置),以获得包含其调用位置的代码段。
错误函数(EF):包含错误位置的函数。
EF的调用者:检查Error函数是否在存储库的其他地方被调用,如果是,检索包含调用位置的代码段。
论文方法(提示词构造)
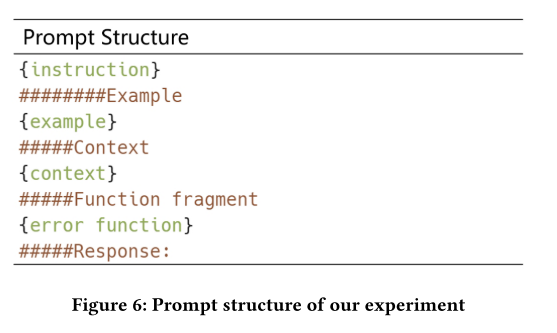
- 定义EIF:
为EIF附加了额外的语义信息,以增强模型对函数目的和参数含义的理解。语义信息由函数签名(signature)和函数摘要(summery)两部分组成。函数签名包括函数名、参数列表中每个参数的类型以及返回值的类型。函数摘要提供了主要功能的概述。任何能够生成代码摘要和签名的模型都可以使用。为了简单和利用llm在代码总结方面的出色性能,我们的实验选择llm作为生成模型。
- EIF调用者
采用切片方法进行处理。由于错误位置包含对EIF的调用,因此对存储库中其他位置的EIF的调用可能具有用于错误纠正的有价值的引用。因此,对于修复任务,来自EIF调用者的代码段中最有用的信息主要集中在调用EIF的语句周围。为了尽量减少引入过多的冗余信息,我们采用了切片方法,保留调用前后语句的内容,每个语句都有一个五行的上下文窗口。
- EF的调用者
对于EF的调用者来说,提供有关错误函数的有用上下文信息可能有助于LLM更好地理解。因此,与EIF的调用器类似,本节的方法也采用了相同的切片方法。
- 误差函数(EF)
在误差函数的上下文中,没有应用额外的处理;相反,它们被直接合并到提示上下文中。
实验
提示词生成
零样本:不提供任何模型示例,仅提供描述任务的自然语言指令。该方法可以最大限度地减少有限的提示长度,并为修复任务提供更多的上下文容量,但也面临任务格式理解等问题。实验采取两种不同的描述方式:简单描述和细节描述
少(one)样本:允许许使用自然语言指令以外的示例来描述任务,实验采取两种不同的描述方式:简单描述和细节描述
COT:已有研究表明,CoT策略可以显著提高llm的推理能力。自动修复错误的过程可以看作是一个推理过程,将修复任务分解为三个不同的逻辑步骤:首先,通过集成上下文信息来识别错误的根本原因;第二,根据识别出的错误原因,制定有针对性的解决方案;最后,生成完整的修复代码。
数据构造
从GitHub上的开源项目收集存储库。为了最大限度地减少由于存储库被用作llm的训练数据而导致的泄漏风险,我们将搜索日期条件设置为晚于2021年10月1日。此外,我们增加了抓取存储库的数量。在本文中,我们主要关注使用Python编程语言的概念验证。因此,我们将工作中考虑的存储库限制为使用Python语言的存储库。同时,我们确保存储库的每个大小不超过1MB,并且它至少有2,000个star。错误部分由专家手工构造,根据与接口不一致相关的错误特征,将发生调用的函数指定为主函数,将被调用的函数指定为上下文函数,下面是构造原则:
•NRV:上下文函数和主函数之间的返回值数量不一致。•NP:主函数和上下文函数之间输入参数的数量不一致。•ORV:主函数和上下文函数返回参数的顺序不一致。•OP:主函数和上下文函数输入参数的顺序不一致。•CRV:上下文函数的返回值与主函数的要求不一致。•CP:主函数与上下文函数的输入参数不一致。
评价指标
为了保证评估结果的准确性,我们最终采用人工评估的方法,评估结果由两位具有5年以上Python编程经验的专家提供。我们将评估指标分为四个项目,以充分评估大模型的返回结果。具体评价标准如下:评价时,如果符合标准,则标记为1;否则,标记为0:
返回结果不为空,与指令中的修复任务有关。•格式正确:返回结果符合预期格式,内容完整,无重复或冗余内容。•正确修复:返回的结果包含错误的正确修复。•正确的解释:此项专门用于CoT提示策略,其标准是返回的结果包含对错误原因的正确解释。
实验结果
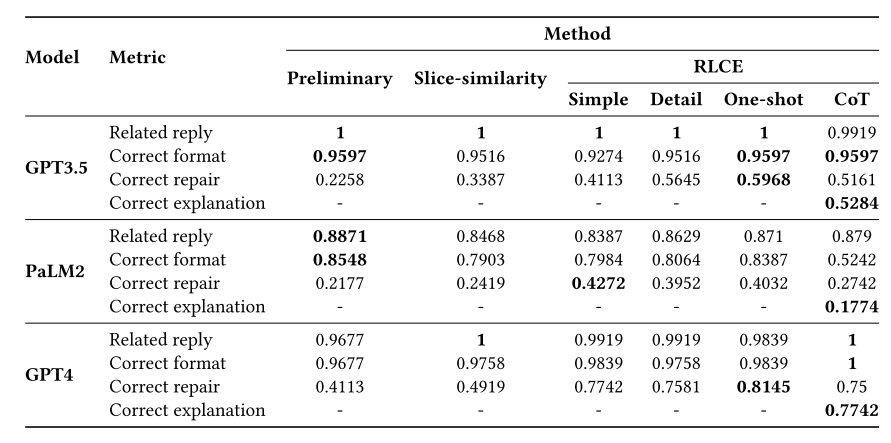
每个单元格表示通过相应评估指标的样本在所有样本中的比例
采用CoT策略的所有模型的修复率都没有达到我们的预期,即使在PaLM2上性能也明显下降。GPT4整体表现最好,但采用CoT策略后修复精度略有下降。
RLCE方法可以显著提高库级程序修复任务,同时使用消融的方式证明之前提到的几种上下文信息源均有用处