【论文阅读】【ACL 25'】SynFix:关系图相关独立性分析的程序修复
论文信息
- 题目:SYNFIX: Dependency-Aware Program Repair via RelationGraph Analysis
- 链接:ACL 25’
主要问题
储存库级别的代码问题分析任务面临一个主要问题:跨组件(文件、类和方法)要求需要对代码库由全面了解。传统方法难以应对该问题,因此本文的主要问题聚焦于有效建模处理大规模代码库之间连系本质的解决方案。
一些基于独立智能体的框架化设计可以使得LLM自主决策,并根据智能体彼此的反馈迭代更新信息。但是限制在于,工具调用的复杂性会引入易出错的抽象层,尤其是将操作映射于API时。缺乏稳健的规划机制意味着智能体经常做出次优决策,另外它们自我反思和过滤不相关或不正确反馈的有限能力也会增大限制。
主要工作在于:
- 关系图驱动的框架:对存储库中的依赖关系进行建模;
- 定位方法和同步过程:分层的定位方法,引入同步机制在链接组件间传播修复信息;
- 验证机制:补丁验证,确保修复正确性
SynFix
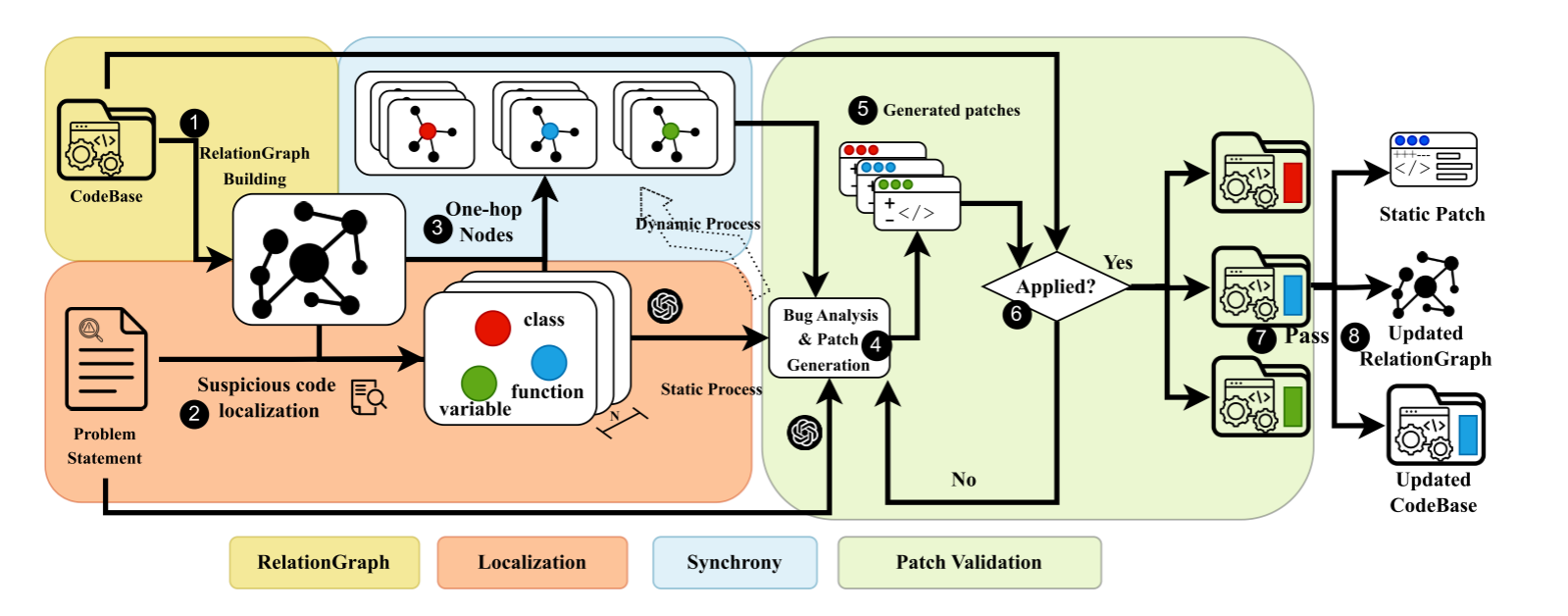
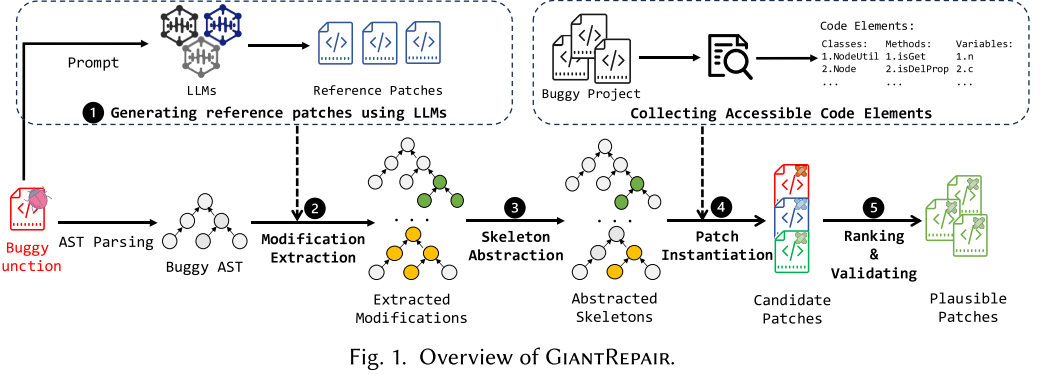
上图为总览,包含以下过程:关系图(①)、定位(②)、同步(③)和验证(④-⑧)。首先构造一个代码库的关系图,捕获其层次结构、变量、类和方法的调用关系,然后通过一个低成本LLM(比如免费使用的GPT3.5)识别排名前N个问题节点及上下文,然后识别问题节点的单跳邻居,提取相应内容,旨在作为LLM的额外输入,并评估是否要对单跳邻居进行更新。模型会动态静态地缩小编辑单位,修复阶段中,SynFix将问题语句和编辑位置呈给LLM,根据提示词生成补丁,然后应用于原始代码库,迭代这个过程,直到补丁应用成功。
关系节点图构建
有向图,节点为代码实体(例如文件夹名、文件名、变量名、类名、函数名),边表示他们的层次或依赖关系(文件夹和子文件夹、文件夹中文件)。如下图实例,该关系图可以视作多个子图按照边关系合并后的结果。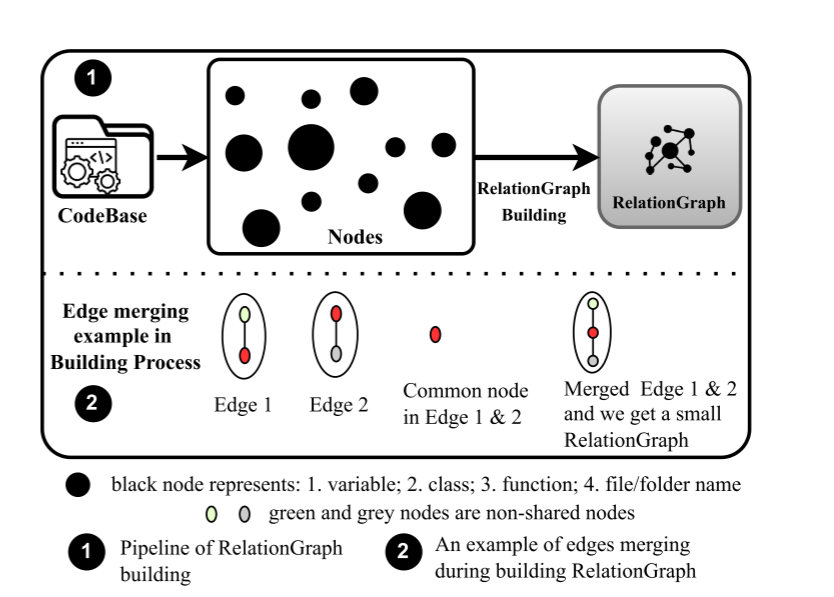
定位
定位过程被拆解为多个步骤:
第一步:可疑节点定位
利用混合检索机制求出前N个可疑节点。
- 基于嵌入的检索:将每个节点转为包含代码片段、注释和相关文件的文本表示,使用OpenAI的
textembedding-3-small计算节点嵌入,利用余弦相似度与问题描述比较,以此确定高相似的前N个节点。 - 基于LLM的重排序:将包含问题描述和提取节点上下文结构化提示交给GPT3.5,重新排序。从此获取可以代码行。
第二步:上下文关注的错误纠正
LLM指导细化定位。
- 静态过程:仅根据上下文进行错误纠正
- 动态过程:合并来自单跳邻居扩展上下文,例如与可疑节点的依赖关系和交互,LLM同时处理直接上下文和这里的扩展上下文提高修复精度。
至此获取问题定位信息和上下文信息。
同步
这一步主要解决修改单个代码实体带来的与其他组件的不一致性问题。若检测到不一致性问题,SynFix提供额外的修改步骤来维持一致性。
简单来说,同步过程首先从关系图中提取单跳邻居,对每个邻居进行一致性检查,检测到不一致性时生成并应用一个纠正补丁更新受影响的节点,该过程将持续迭代。
补丁验证
检查:补丁是否解决了识别问题,并且还能保持原有功能,重点检查语法、回归行为,若出现问题,则为新的问题节点生成补丁,迭代该过程。
实验
数据集
- SWE-bench
- BigCodeBench
基线和评估标准
基线多选SWE-bench的极限方法,涵盖基于代理、无代理或检索增强生成。评估标准如下:
- 解决百分比(***%Resolved***):在数据集中解决问题的百分比
- 平均代价(Avg. $Cost):每个问题的平均推理成本,反映了计算效率
- 平均Token数量(Avg. $Cost):表明LLM的资源消耗
结果
- 实验一:效率表现:

- 实验二:消融:

- 实验三:基础LLM对比: