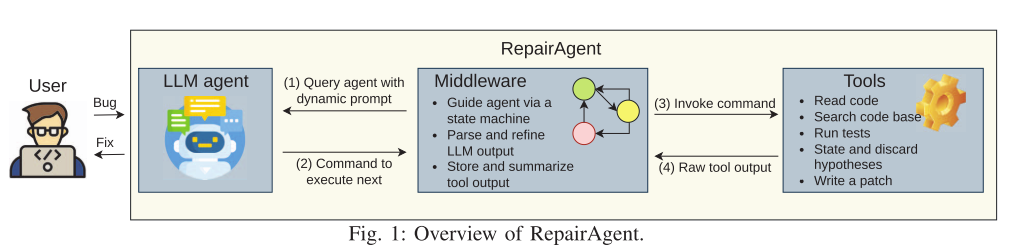
【论文阅读】【ISSTA 24'】Think Repair:自我导向的自动程序修复
论文信息
题目:ThinkRepair: Self-Directed Automated Program Repair
链接:ISSTA
主要问题
现有的自动修复通常依赖于预定义的模板(提示词),而预定义的模板依赖于数据集质量,而思维链(CoT,Chain of Thought)提示提高了推理性能。综上,ThinkRepair提出的是一个结合思维链分析的大语言模型修复框架。可行性在于:无监督的训练方式使得LLM保有强大推理能力,而少样本的思维链可以逐步增强这个能力。
文章贡献在于:
- 自导向的LLM自动修复框架;
- 推理能力增强:少样本思维链+自动化思维链构建、选择和互动;
ThinkRepair
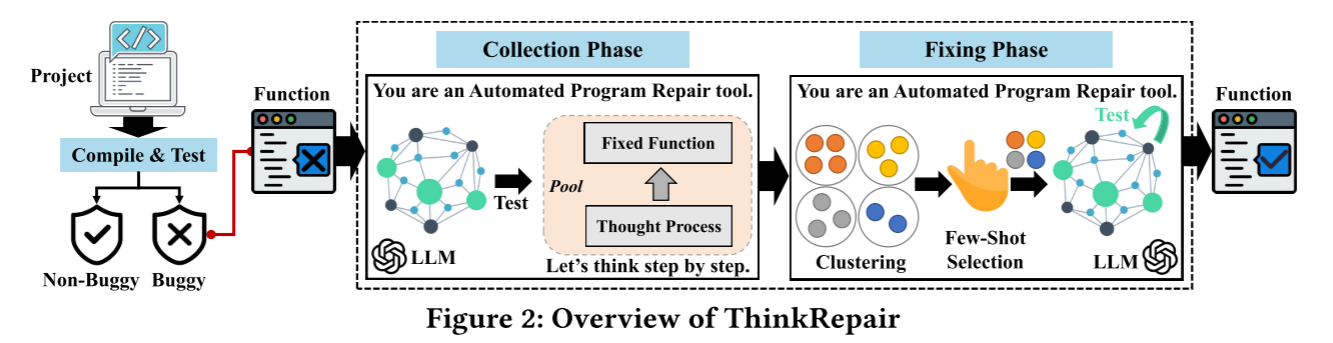
包含两个阶段,收集和修复。前者收集构成预先知识的思维链并生成知识库,后者利用少样本思维链提示学习缺陷修复。
理论前提
- 大模型:包含数十亿个代码token进行无监督训练保证推理能力,且无需依赖已有错误信息标注即可应用。
- 针对自动程序修复的少样本思维链:通常修复过程包含一连串中间步骤,依托少量样本,从LLM中提取思维链进行学习,并且使用CoT组合结果的提示进行修复生成。
阶段一:收集阶段
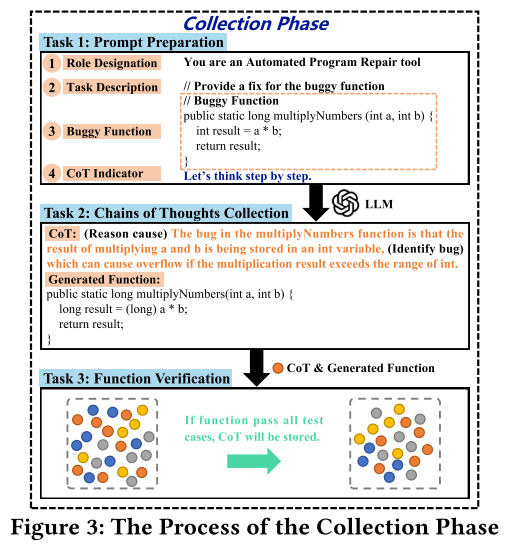
以下分步骤进行:
步骤1:提示词准备
不多说,详见上图的“Prompt Preparation”提供的单函数示例。
步骤2:收集思维链
给定一个缺陷函数库,ThinkRepair用提示收集CoT。这个步骤输出一个样本集合,每个样本包括一个bug行数、修复版本和CoT。
步骤3:功能验证
需要过滤掉低质量的思维过程。此步会过滤掉原有数据中未通过所有样本(case)的情况。对于每个缺陷,设置测试次数上限为25.
阶段二:修复阶段
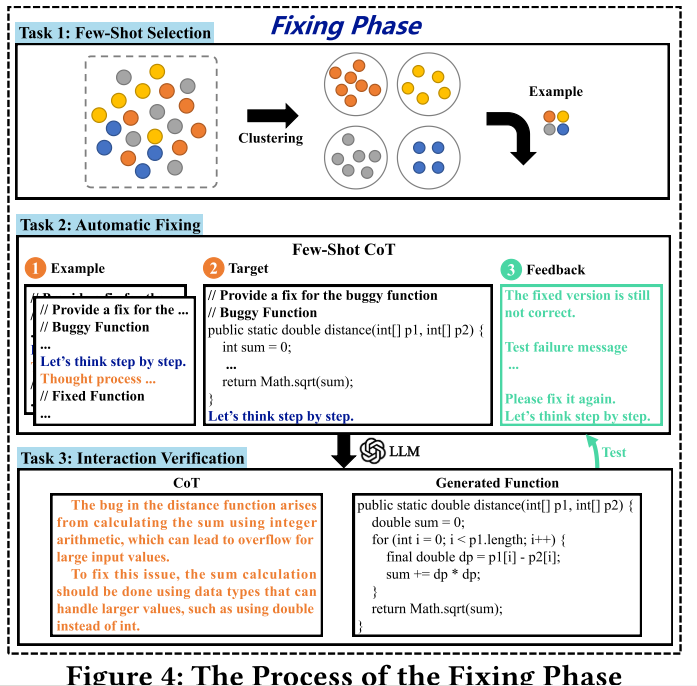
首先从之前的直属库中筛选出多样有效的样本。首先将选定的示例(bug函数和相应的带有推理过程修复版本)和目标bug函数组成提示符与LLM交互。最后,从LLM获得输出:思维链和候选的修复函数。每个生成的候选函数都会经过一个验证步骤。该阶段有三个任务:
任务1:少样本选择
目的是为LLM提供优质的提示,并且尽可能减小成本。方法是,基于语义相似度聚类,从每一种聚类中选择一个样本。语义相似度的具体方式有:
- UnixCoder+余弦相似度
- 利用对比学习框架R-Drop微调UnixCoder来获取更优质的嵌入,两次输入一个函数,训练目标为缩小这两次训练得出嵌入的差距
- 基于IR选择,通过BM25分数检索相似示例
- 随机选择
任务2:自动修复
构造提示符,上图的①②,包含修复示例、bug函数。
任务3:交互验证
如果生成的候选函数没有通过所有用例,首先收集失败的测试信息,后期提供指导。失败信息可以分为四类:编译失败、超时、语法错误、测试失败,然后重构提示,将失败信息附加到后面,如上图的③。此时提示模板固定,如图所示。最大交互次数设置为5.
实验
数据集
Defects4j、QuixBugs
基线、评估指标
8种NMT(自然语言翻译,将bug翻译成不bug的)和4种基于LLM的。详见下表: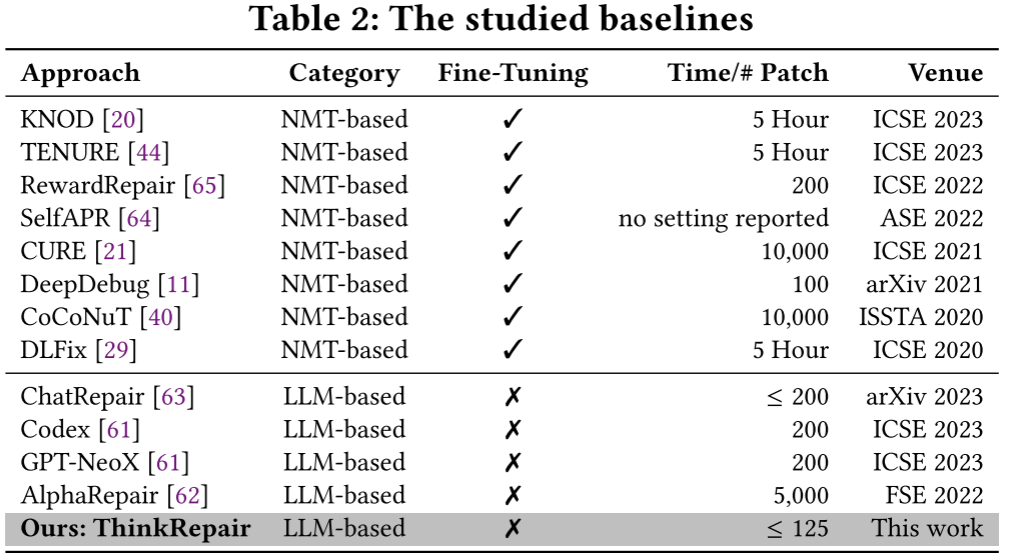
评估指标为两个:正确补丁数量(可以通过所有用例,但是不保证语义等同于修复)和可信补丁数量(语义上等同于实际修复)。
结果
- 对比LLM的方法
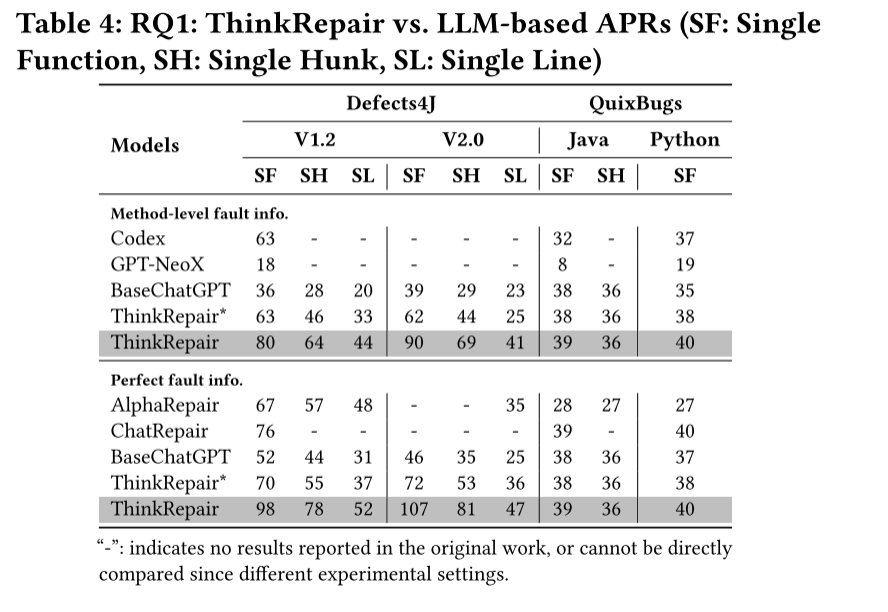
- 对比NMT的方法