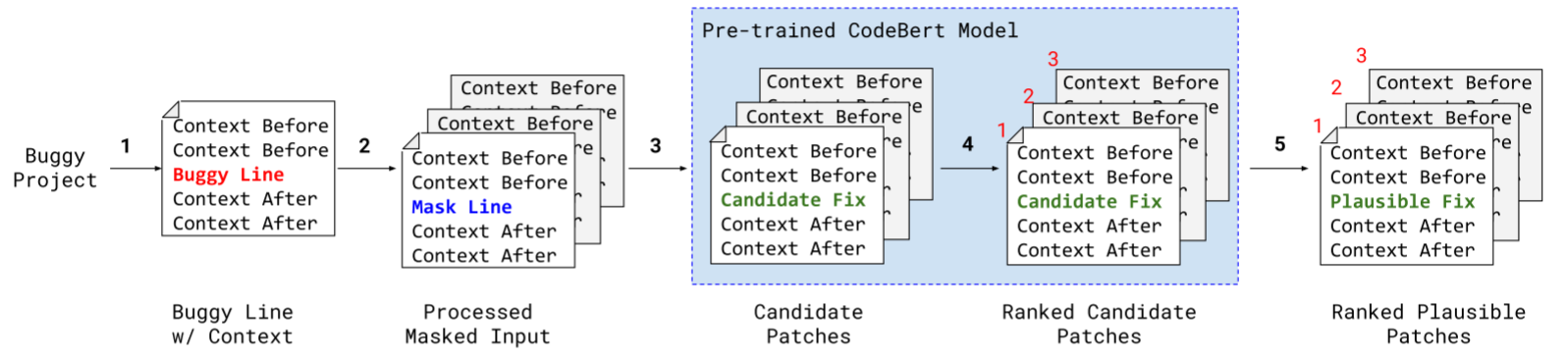
【论文阅读】【TSE 25'】Contrast Repair:通过对比测试用例对增强基于对话的自动程序修复
论文信息
- 题目:ContrastRepair: Enhancing Conversation-Based Automated Program Repair via Contrastive Test Case Pairs
- 链接:TSE
聚焦问题:
LLM驱动的修复方法多采用对话形式,其有效性取决于提示词的质量。Contrast Repair为对话提供对比测试来强化对话驱动的修复过程,一个测试对由通过和未通过的两个样例构成。其关键思想在于,仅仅依赖未通过的测试样例不足以让llm精确地定位错误,而来自成功测试的正反馈可以补充。挑战在于,选择适当的通过测试用例和失败用力配对,最小化其差距来定位错误原因。主要贡献如下:
- 对比思想驱动会话驱动的LLM修复方法
- 提出一种构建合理测试对的方法,其中包括成功和失败的两种样例选择
- 全面的评估
文章提供了一个样例来说明正负用例在定位错误方面的重要性。样例中的代码无法正确处理0X和0x中的大小写字母从而导致输入用例0Xfade未正确输入,但是0x和-0x均正确输入。搭配正确的正负样本对直接对ChatGPT的修复结果起到决定性作用,因此在定位bug时,找到这样的两个用例对很关键。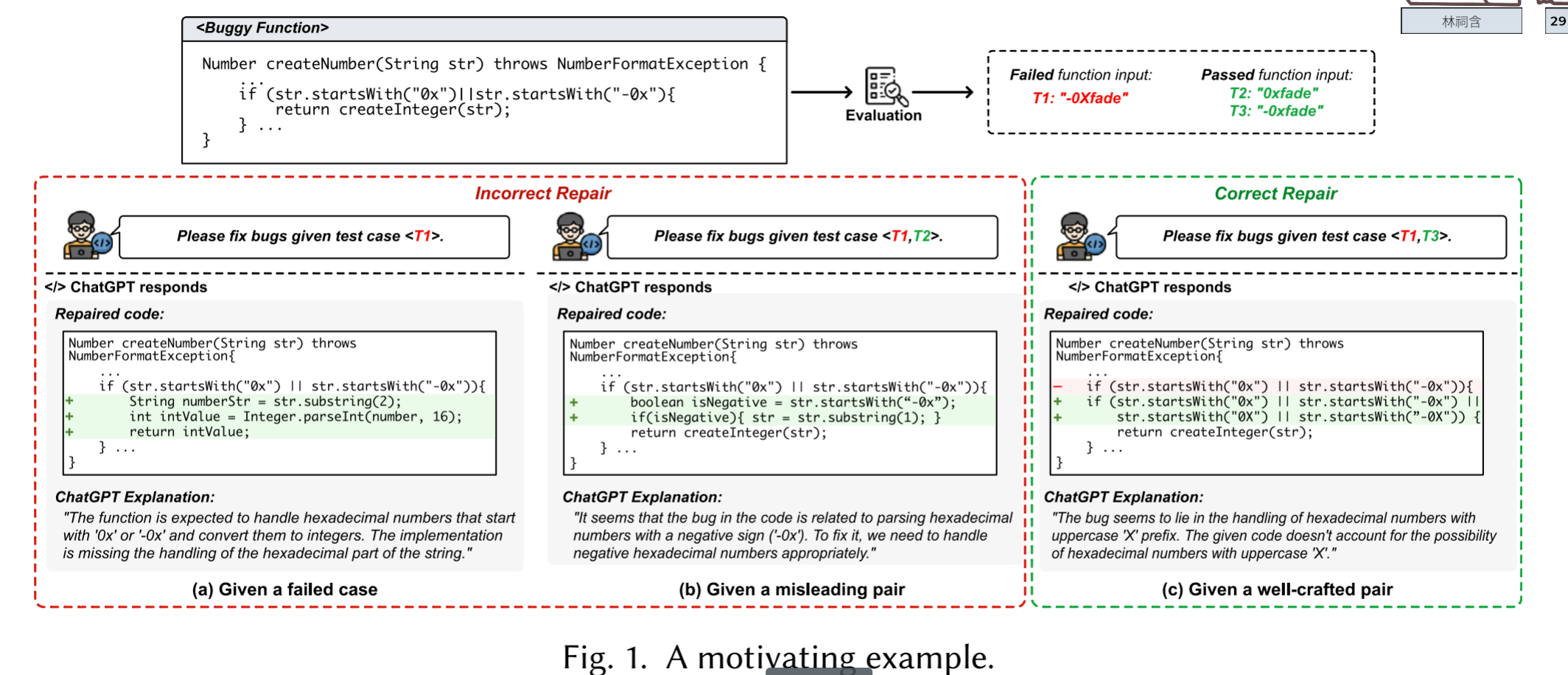
Contrast Repair
概述

Contrastrepair本质上是由一个对比测试对构造提示词的LLM修复方法。具体来说,在每次对话的迭代中,将一个要验证的程序程序作为输入,以及一个由多个测试用例组成的测试套件。假定初始程序是有bug的代码。然后,ContrastRepair用测试套件评估程序。如果所有测试都成功通过,则获得一个合理的补丁,由人进一步研究。如果程序产生错误(f)并处罚程序错误,则捕获回溯日志(Tf),此外还收集程序正确处理所有通过的用例和未通过的用例。为了从这些用例中找出有指导意义的用例对,提出一种相思引导的学则过程。Delta调试旨在通过最小化失败用例和通过用例间的差异来寻找错误原因(?)。受此启发,contrastrepair用一个与失败测试差异最小的通过测试来定位错误,然后未llm构造结构化提示词。为了收集bug的依赖信息,我们从失败测试用例的回溯中识别依赖函数。提示符由来自失败测试用例f的回溯日志、构造的测试对、依赖函数、目标错误函数和需求描述组成。有了这个提示,ChatGPT生成修复后的代码,然后在随后的迭代中进行验证。迭代过程继续进行,直到确定了一个合理的补丁或达到了修复预算。
构建对比用例对
- 相似度度量法
要确保通过和失败用例对的差异够小,contrastrepiair选择的相似度度量算法为Damerau-Levenshtein距离计算字符串相似度,通过量化将一个字符串转换为另一个字符串所需的最小操作次数来衡量两个字符串之间的相似性。 - 通过用例
为了收集通过测试用例,采用两种策略:现有的生成的。现有用例来自开源数据集,contrastrepair则提出一种基于最小化失败用例更改的类型感知的突变方法来生成新的用例。
类型感知突变包括两个主要组成部分:基于字符串的通用突变和特定类型的突变。考虑到相似性是基于字符串表示度量的,自然的方法是首先将失败的测试f转换为字符串表示。然后,我们执行字符串级别的突变,同时限制突变的程度。最后,我们将字符串变体转换回其原始类型。另外,我们使用特定类型的突变来增强生成的测试用例的多样性。突变策略如下:1
字符串突变:(1)随机字符替换;(2)随机子串替换;(3)随机字符插入;(4)随机字符删除;(5)子串交换;(6)大小写转换(7)截断/扩展。-整数、双精度和浮点数突变:(1)随机扰动,增加或减少一个小的随机值;(2)缩放,乘以缩放因子;(3)翻转符号,从正变为负或反之亦然;(4)幅度摄动,增加或减少数字幅度的一小部分。-字符突变:用随机选择的不同字符替换原始字符(随机替换)。-Boolean突变:否定布尔值(Negation)。-对象突变:元素智能突变是基于上述基本类型的突变。-数组,列表:(1)元素明智的突变,改变一个或多个元素;(2)元件交换;(3)插入元件;(4)元素删除(5)元素洗牌。
对话驱动的LLM修复
修复流程遵循迭代原则。有两种策略:
- 从上一次补丁继续,在之前尝试修复的基础上构建,但是修复流程还是会朝着错误方向继续。
- 从原始的bug函数重新启动修复,每次迭代都从最干净的状态重启,但是丢失了持续反馈的流程。
为了寻找平衡,本文用的是结合方法,在规定的迭代次数中若未完成任务就重新开始。
提示词模板: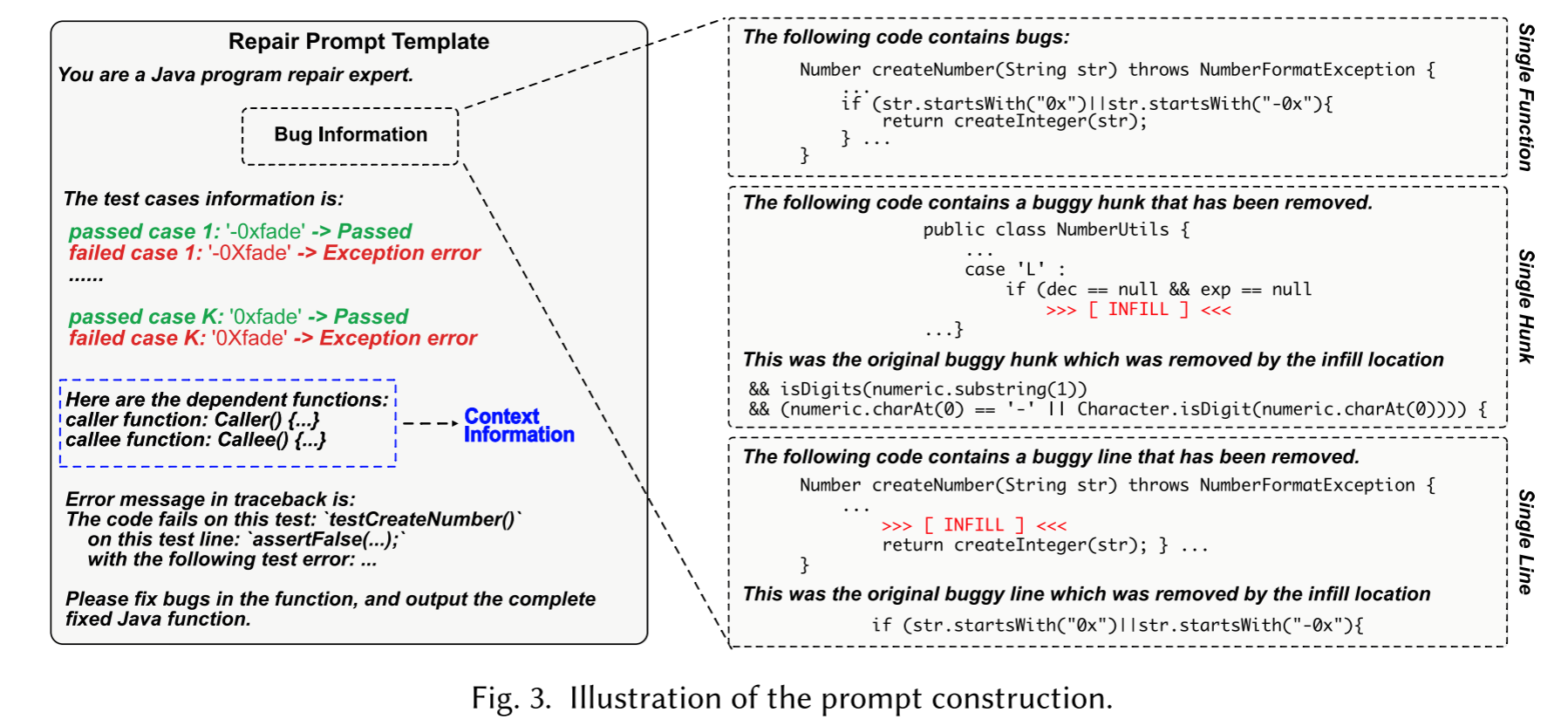
实验
实验RQ:
- 与最先进的APR技术相比,ContrastRepair的效果如何?我们通过将其与传统的APR方法、基于深度学习的APR技术和最近的对话驱动APR工具进行比较,来评估ContrastRepair的性能。
- ContrastRepair在未知数据集中有多有用?考虑到llm造成的潜在数据泄露风险,我们在以前未见过的数据集上评估了ContrastRepair,这些数据集在ChatGPT的训练过程中没有使用。
- 不同的超参数是如何影响contrastrepair的修复性能的?包括测试对的数量,以及持续修复和重新启动修复的阈值
- contrastrepair的不同组件在提高修复效率方面的贡献是什么?我们的目标是了解ContrastRepair的每个组件的有用性,包括对比测试对和相关函数。
实验设置
- 数据集:defect4j、QuixBugs、HumanEval-Java
- LLM选取:ChatGPT3/GPT-3.5-turbo-0301.均为API
- 采样温度:1
- 尝试连续/重启修复最大次数:3/40,所以每个函数修复最大会话数是120
- baseline:TBar、SelfAPR[75]、AlphaRepair[68]、rewarrepair[76]、Recoder[84]和CURE[36]以及一种使用无详细反馈的LLM修复方法BaseChatGPT。
- 评价标准:正确修复#Correct:该度量计算了基于每个工具生成的合理补丁的手动审查而正确修复的程序的数量、ChatGPT查询数#Query:评估了所有错误案例中ChatGPT API查询的平均次数,提供了对ChatGPT调用所需频率的洞察。
RQ1对比测试:
Defects4j数据集上的对比结果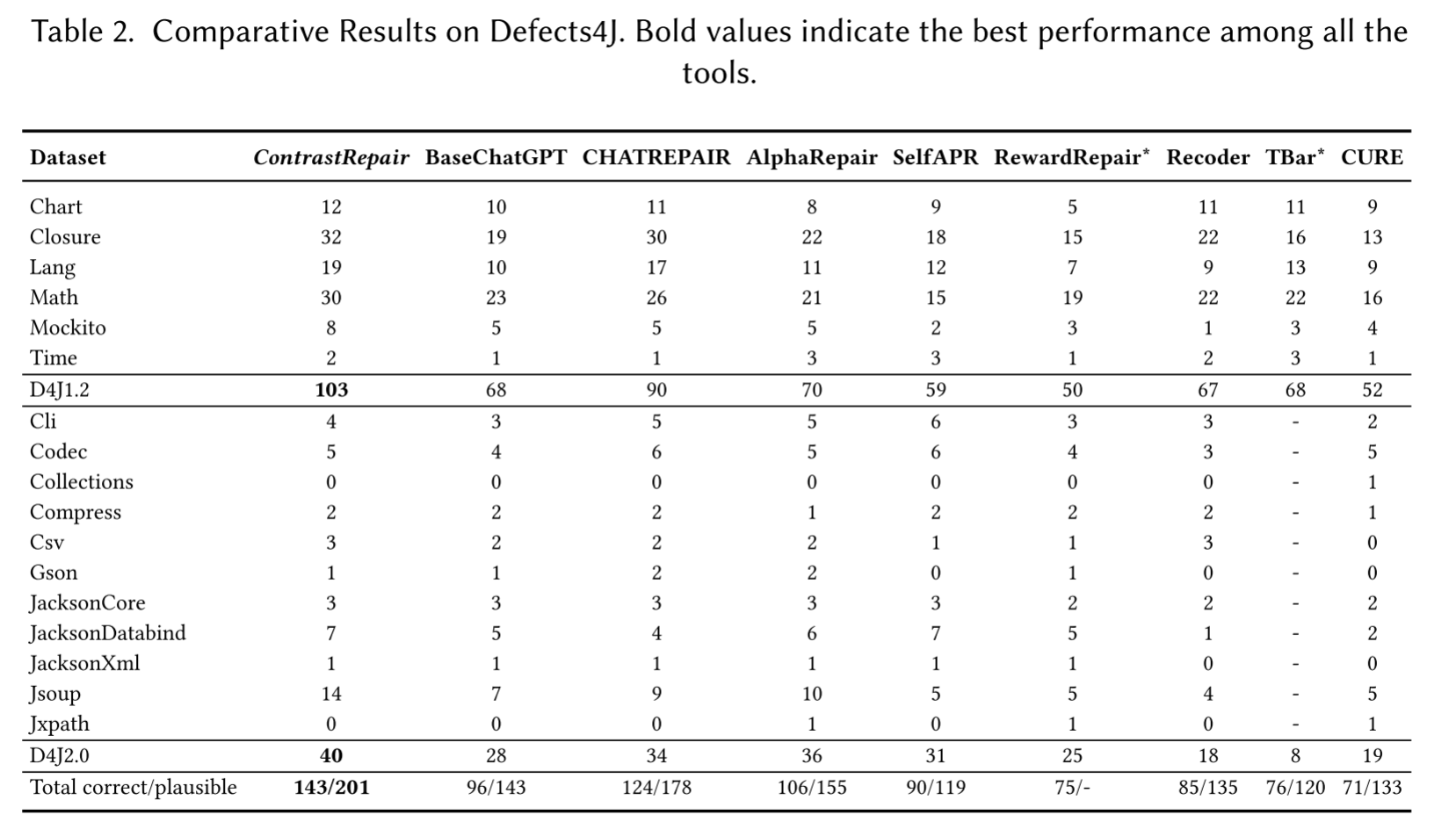
QuixBugs数据集上的对比结果
对于变异策略的验证(下图表示变异前后的相似度分数),突变策略显著提高了相似性得分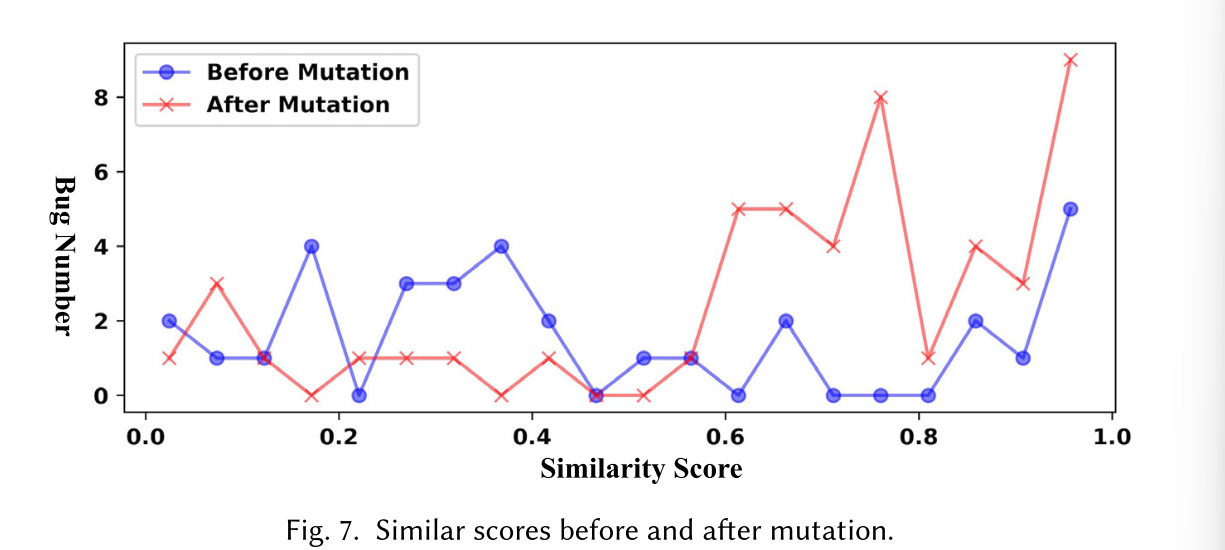
RQ2泛化性测试:
Defect4j等数据集可能存在数据泄露,所以提供一种最新引入的HumanEval-Java数据基准。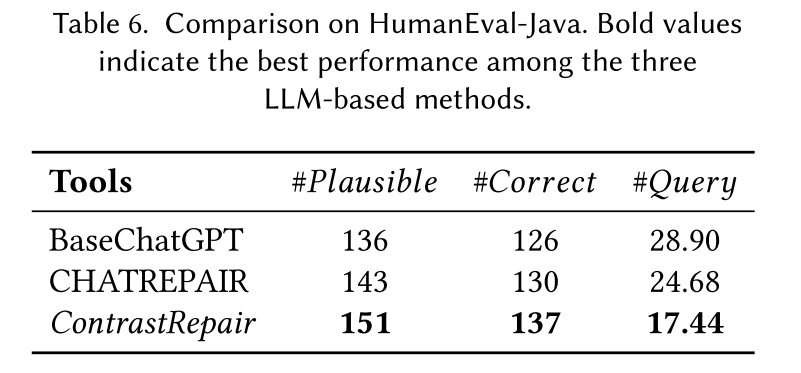
RQ3:超参数研究
研究对象为测试用例对数(k)、尝试连续/重新修复的最大次数(m/n)。下表为结果: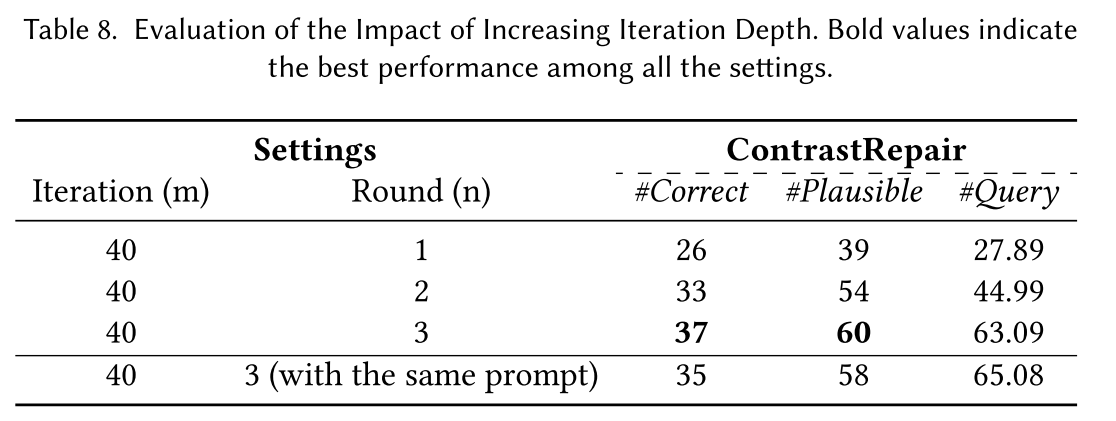
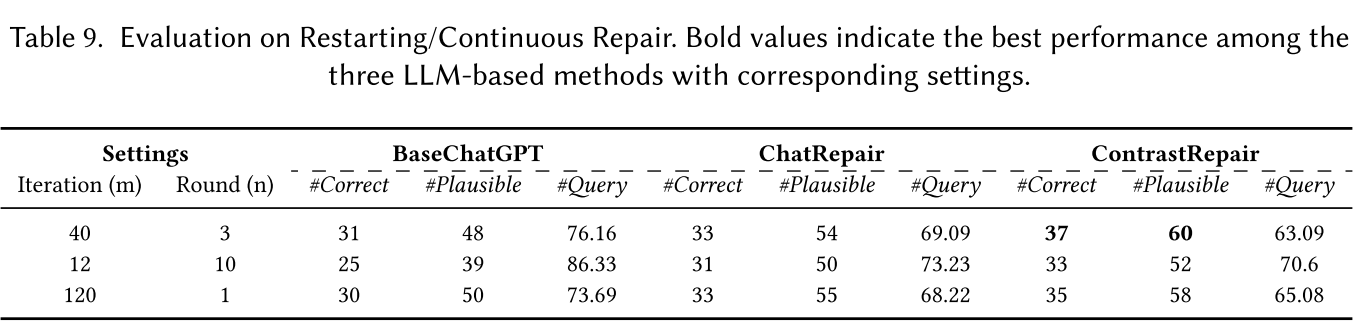
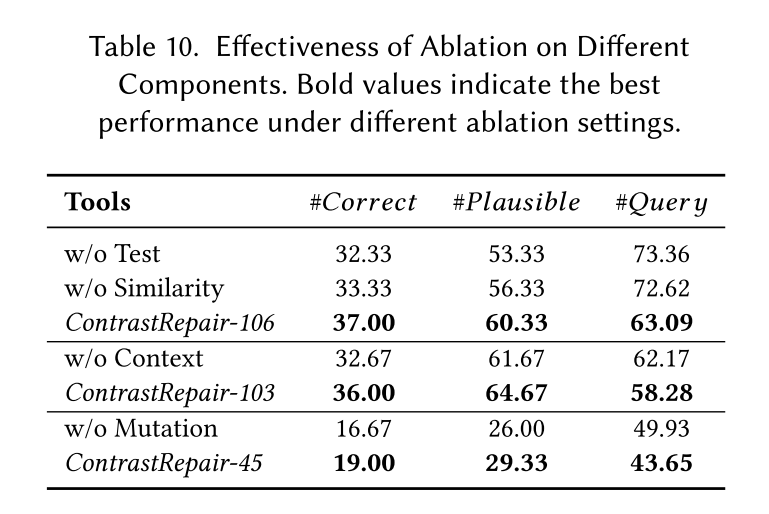
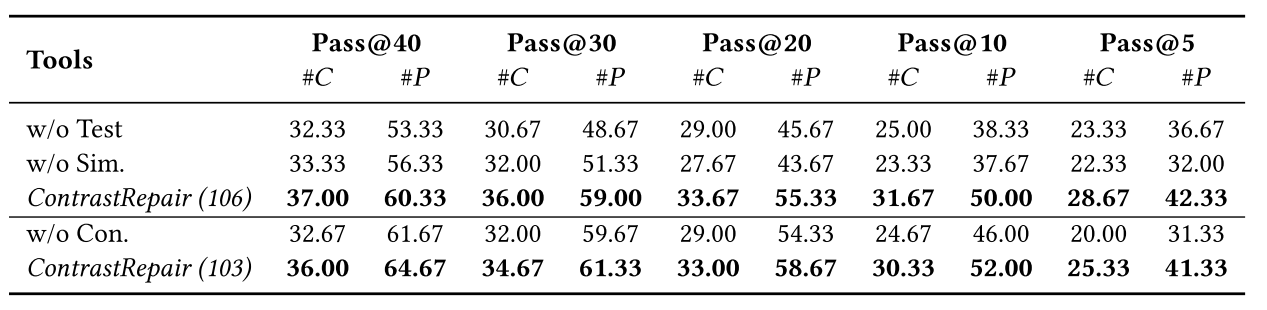
RQ4:消融
研究对象为是否含有正、负样本对(w/o test),并且设置用相似性选择生成代替突变的实验来证明突变的必要性(w/o Similarity)。 结果: