
【论文阅读】【ICSE 25'】大语言模型时代的模板引导程序修复
论文信息
- 题目:Template-Guided Program Repair in the Era of Large Language Models
- 链接:ICSE
聚焦问题:
基于模板的修复方法被盲目使用及其覆盖范围的不足使得该方法在领域内存在局限,此外,在零样本学习情境下使用小型LLMs也被证明并非最优选择。集体来说,其主要缺点在于:1. 不加选择地使用模板,不加选择地使用所有可用的模板。具体来说,GAMMA利用基于ast的匹配方法来选择修复模板,这有可能导致模型错过正确的补片合成机会,加剧补片过拟合问题。2. 模板覆盖不足:基于模板的APR工具的有效性本质上受到其模板范围的限制。3. 零样本下小规模llm的局限性,而在微调范式下具有模板的十亿级llm的潜力尚未开发。
可行性建立在三个共识上面:
- 训练模型对模板进行排名。可以开发一个模板排名模型,利用LLM的代码理解能力。
- 神经机器翻译(NMT)工作流通过将修复任务概念化为翻译而不是填充任务来规避模板覆盖问题。在这个工作流程中,我们可以设计一个特殊的模板来表示传统模板集之外的bug修复,并采用NMT模型来学习这些复杂的修复行为。
- 应用NMT微调策略可以克服与零样本学习范式相关的局限性。考虑到llm本身不是为修复任务量身定制的,我们可以在微调期间将模板的错误修复知识传授给llm。此外,NMT工作流程的灵活性使其能够适应各种模型架构,而不局限于基于mlm的llm。
NTR将修复任务分为模板选择和补丁生成两个阶段。1)在模板选择阶段,NTR将其制定为多类分类问题,并微调轻量级llm作为模板选择模型,进行模板排序。2)在补丁生成阶段,我们采用NMT工作流,并将选择的模板格式化为指导。我们选择了一个具有数十亿个参数的LLM,并在NMT工作流程下对其进行微调。在微调过程中,我们引入符号来表示有bug的代码、模板和固定的代码。这使得llm能够以自回归的方式合成补丁,自然地遵循所选模板的逻辑。为了解决模板覆盖问题,我们建立了一个特殊的模板以捕获超出现有模板范围的修复行为。
NTR
NTR的工作流分为模型微调和模型推理两个主要部分,设计选择上有两个模块,首先训练一个模板选择模型,对有bug的代码优先考虑合适的修复模板,然后训练一个补丁生成模型,在模板的指导下进行补丁合成。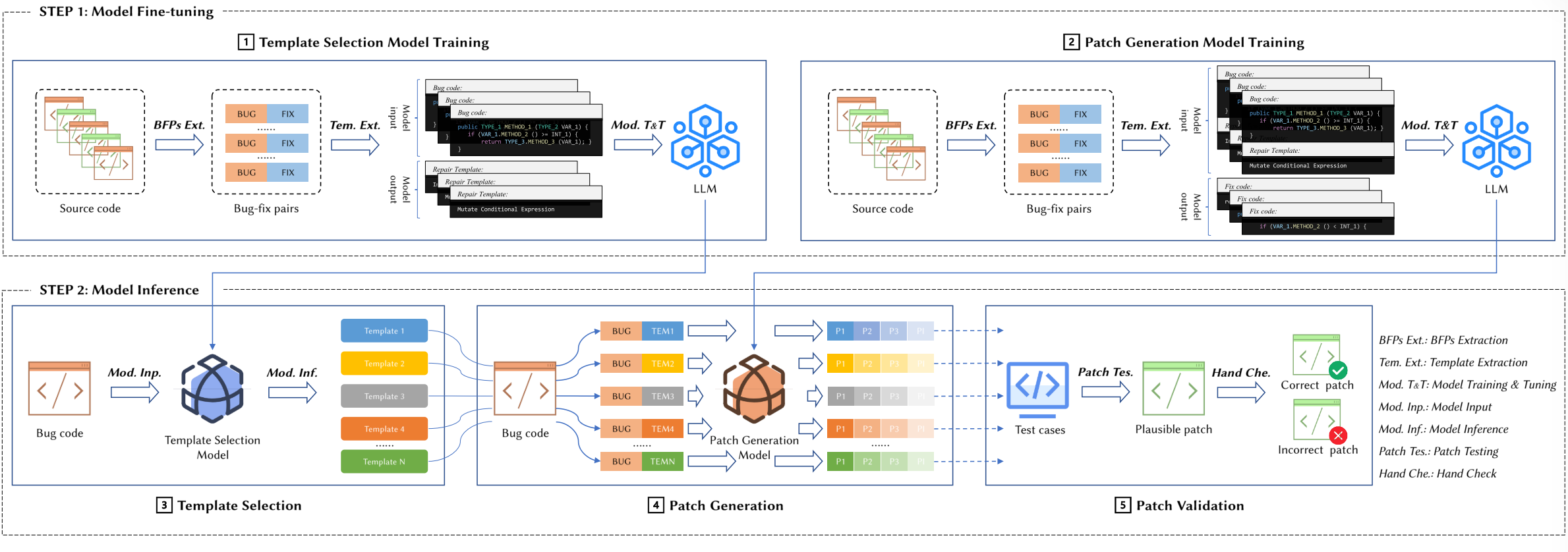
模型微调
模板排序和补丁生成。
- 模板选择模型训练:要考虑模板的有效性,所以使用NMT微调范式来训练一个模板选择模型。训练步骤:
- Bug-修复对提取:提取出函数级别的BFP(Bug-Fix pair)。
- 模板提取,获取bfp后针对性产生修复与模板,基于最先进的基于模板的APR工作进行这一步。
- 模型训练和微调,训练目标在于最小化模板选择模型的交叉熵。
在模板选择模型的训练过程中,我们使用小规模的llm(如CodeT5)作为基础模型。
- 补丁生成模型训练
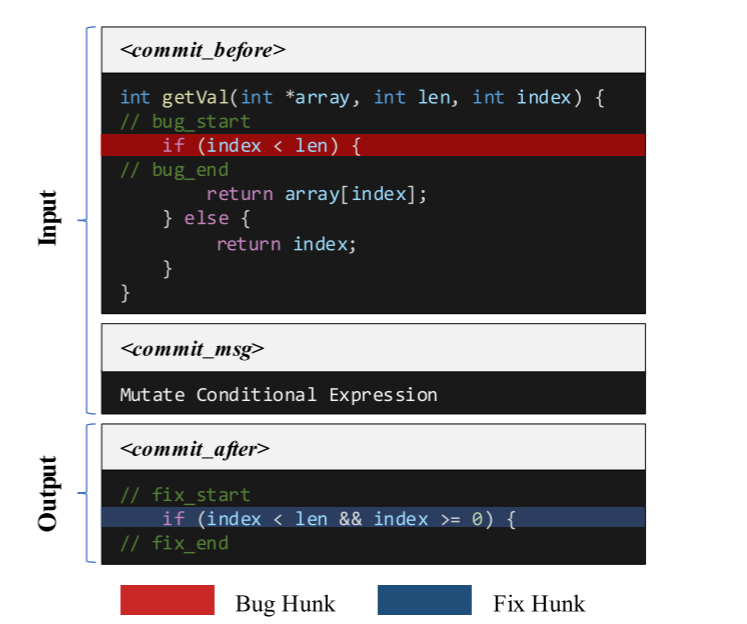
通过对模板选择和补丁生成进行独立优化,从而独特地协调模板选择和补丁生成。在补丁生成阶段,我们特别将选择的修复模板与有bug的代码一起作为输入,而将固定的代码单独指定为输出。这种双输入方法使贴片合成过程更接近于所选模板提供的指导。在微调阶段,我们将bug代码、模板和修复代码格式化,如下:
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 西风的那一年!
相关推荐
2025-10-19
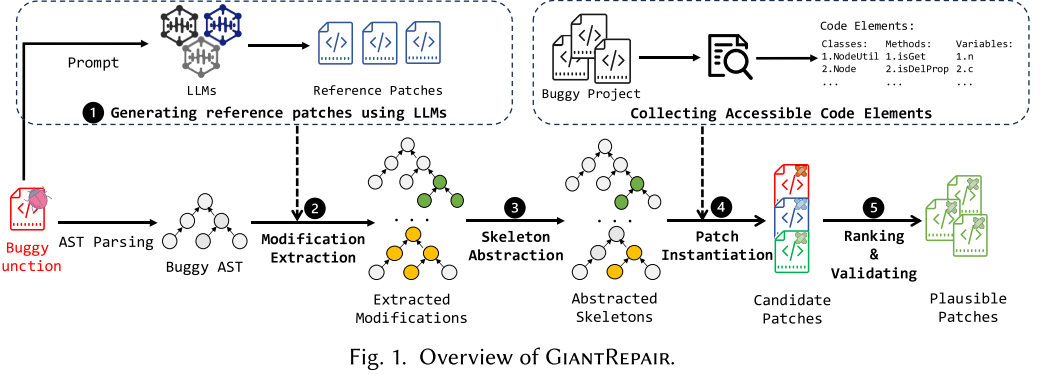
【论文阅读】【ToSEM 25'】Giant Repair:结合大型语言模型和程序分析的混合自动程序修复
论文信息题目:Hybrid Automated Program Repair by Combining Large Language Models and Program Analysis链接:Tosem 主要问题文章提出,现有的基于预定义修复模板、启发式规则和约束求解的自动程序方法难以充分利用实际应用中各种补丁的大搜索空间。其局限性在于: 基于LLM的APR方法直接利用生成补丁,没有进一步的优化。LLM通常难以生成一些有关于特定程序元素的修复方案,比如局部变量和特定域方法调用等。如何利用这些不完善的修复方案来提高整体修复能力也是一个待探索的领域。 迄今为止,APR方法评估是在漏洞已被定位的前提下进行的。这种场景并不现实。本文章的主要贡献在于: 提出GiantRepair,利用LLM输出的“并非完全正确”的补丁,从其中提取补丁骨架进行整体方法的优化; 在两种应用场景下进行优化评价; 开源:...
2025-10-14
【论文阅读】【NeurIPS 24'】MAGIS:多智能体支撑的大语言模型Github问题解决——通过精心设计的智能体协作来增强问题解决能力
论文信息: 题目:MAGIS: LLM-Based Multi-Agent Framework for GitHub Issue ReSolution 链接:NeurIPS 24’ 主要问题类似Github的代码托管平台,其项目通常不是一成不变的,开源软件作者会更新多个版本,并将源码按照版本号推至代码仓,本文的根本目的是解决开源代码产生的各类“issue”,同时研究了多智能体应用对该下游任务的优化性能。本文的主要贡献如下: 我们对llm解决GitHub问题进行了实证分析,探讨了定位代码文件/行、代码变更的复杂性与解决成功率之间的相关性。 我们提出了一种新的基于llm的多智能体框架MAGIS,以减轻现有llm在GitHub问题解决上的局限性。我们设计的四类代理及其在规划和编码方面的协作都释放了llm在存储库级别编码任务上的潜力。 我们在SWE-bench数据集上比较了我们的框架和其他强大的大语言模型竞争对手(即GPT-3.5,...
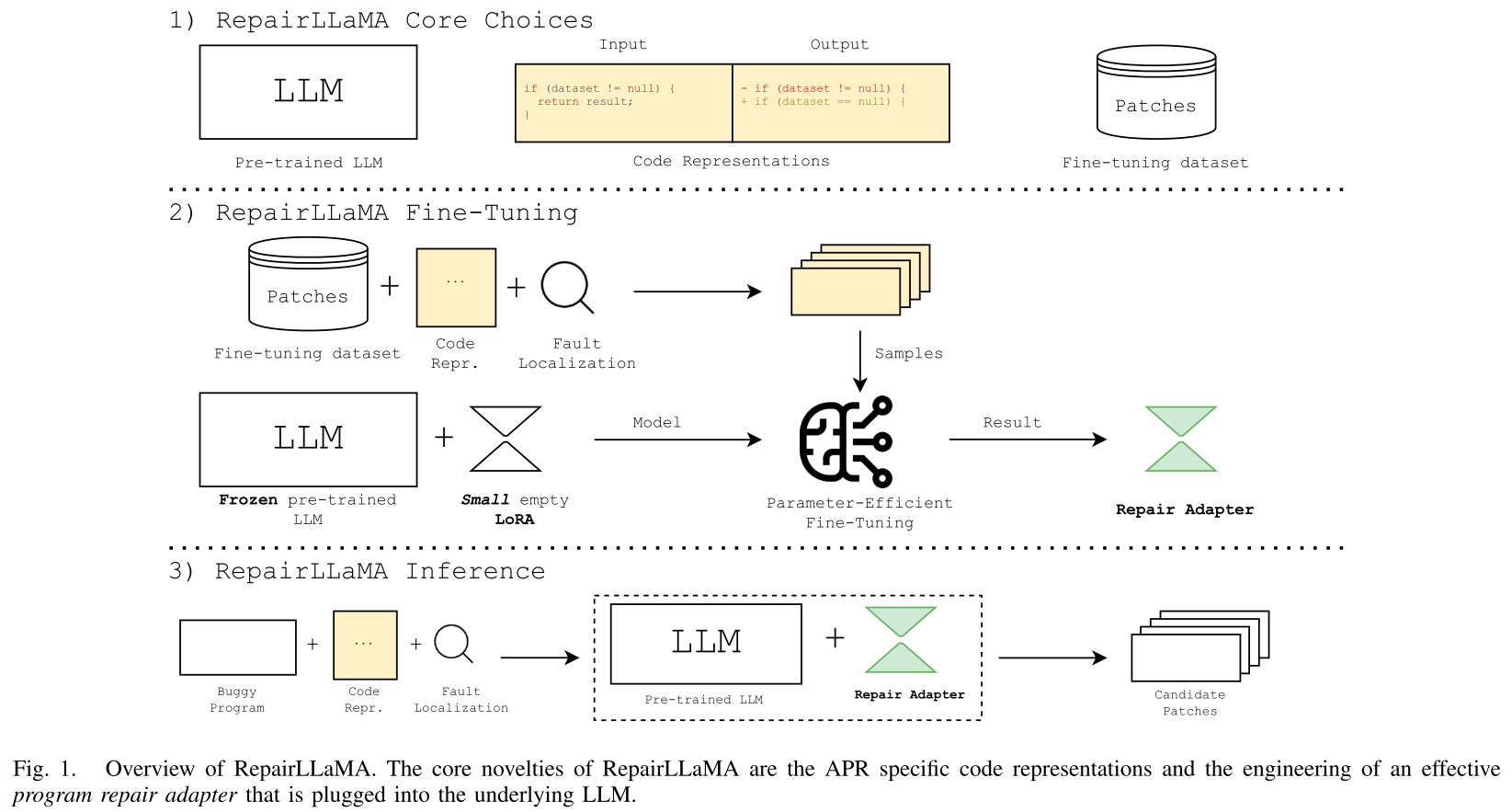
2025-12-15
【论文阅读】【TSE 25'】RepairLLaMA:程序修复的有效表示和微调适配
文章信息 标题:RepairLLaMA: Efficient Representations and Fine-Tuned Adapters for Program...
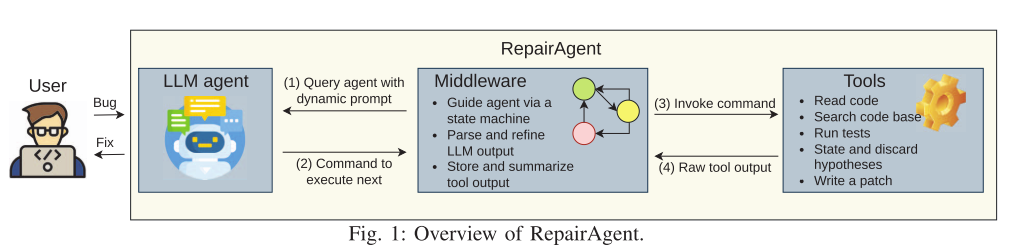
2025-10-15
【论文阅读】【ICSE 25'】RepairAgent:自主的基于大语言模型的程序修复智能体
基本信息论文题目:RepairAgent: An Autonomous, LLM-Based Agent for Program Repair链接:ICSE...

2025-12-14
【论文阅读】【TSE 25'】Contrast Repair:通过对比测试用例对增强基于对话的自动程序修复
论文信息 题目:ContrastRepair: Enhancing Conversation-Based Automated Program Repair via Contrastive Test Case Pairs 链接:TSE 聚焦问题:LLM驱动的修复方法多采用对话形式,其有效性取决于提示词的质量。Contrast...
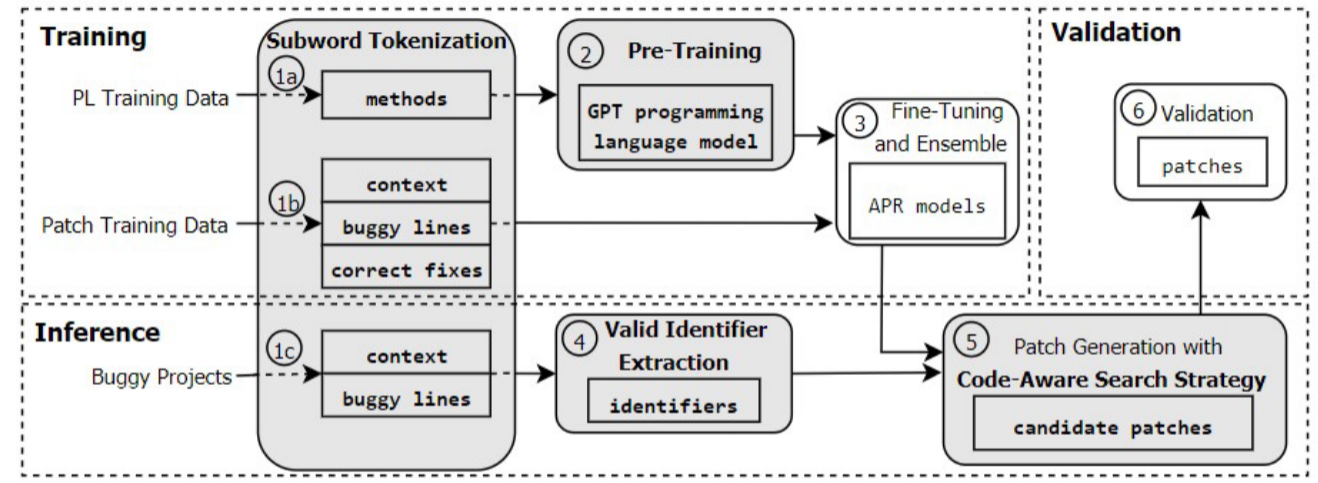
2026-01-04
【论文阅读】【ICSE 21'】CURE:用于自动程序修复的代码感知神经机器翻译
论文信息 题目:CURE: Code-Aware Neural Machine Translation for Automatic Program...
评论




