
【论文阅读】【ICSE 21'】CURE:用于自动程序修复的代码感知神经机器翻译
论文信息
- 题目:CURE: Code-Aware Neural Machine Translation for Automatic Program Repair
- 链接:https://arxiv.org/pdf/2103.00073
主要问题
神经机器翻译(NMT)技术有两个主要的局限性。它们的搜索空间通常不包含正确的修复,而且它们的搜索策略忽略了诸如严格的代码语法之类的软件知识,例如上下文信息。由于这些限制,现有的基于nmt的技术不如基于模板的最佳方法。
CURE
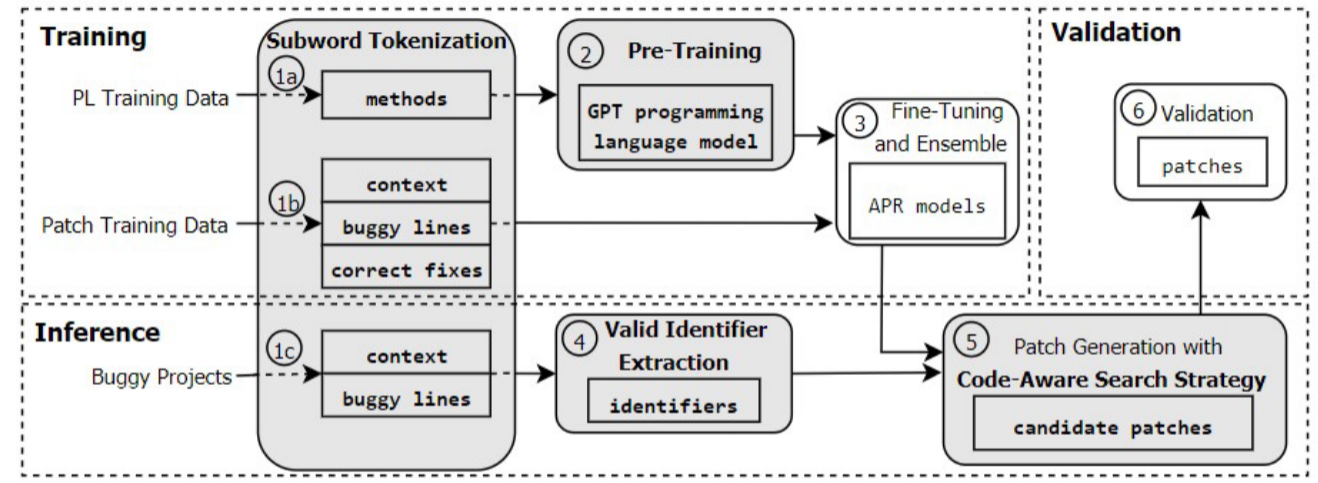
包含三个阶段,训练、推理和验证。训练阶段,CURE从开源项目中提取函数集代码,并对它们进行子词tokienize。CURE使用这些标记化的方法来训练一个新的编程语言模型,该模型学习具有正确语法的开发人员源代码,还将从开源项目的提交历史中提取的错误行、上下文和正确的修复(称为补丁训练数据)标记为标记序列,使用它们对APR模型进行微调。推断阶段,用户向CURE提供有bug的项目以及有bug行的位置。CURE对有bug的行和上下文行进行标记(步骤1c),然后分析源代码以提取在有bug行范围内的有效标识符列表(步骤4)。补丁生成模块使用新的代码感知波束搜索策略(第5步)生成候选补丁列表。这个新算法在运行中丢弃许多不相关的补丁(即,一旦生成无效的令牌),并惩罚不太可能正确的补丁(例如,与错误行非常不同的补丁)。验证阶段,CURE通过编译和执行补丁项目的测试套件来验证候选补丁。CURE输出一个合理的补丁列表(步骤6 ~ 9)供开发人员检查
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 西风的那一年!
相关推荐
2025-10-15
【论文阅读】【ICSE 25'】RepairAgent:自主的基于大语言模型的程序修复智能体
基本信息论文题目:RepairAgent: An Autonomous, LLM-Based Agent for Program Repair链接:ICSE...
2025-12-15
【论文阅读】【ICSE 25'】大语言模型时代的模板引导程序修复
论文信息 题目:Template-Guided Program Repair in the Era of Large Language Models 链接:ICSE 聚焦问题:基于模板的修复方法被盲目使用及其覆盖范围的不足使得该方法在领域内存在局限,此外,在零样本学习情境下使用小型LLMs也被证明并非最优选择。集体来说,其主要缺点在于:1. 不加选择地使用模板,不加选择地使用所有可用的模板。具体来说,GAMMA利用基于ast的匹配方法来选择修复模板,这有可能导致模型错过正确的补片合成机会,加剧补片过拟合问题。2. 模板覆盖不足:基于模板的APR工具的有效性本质上受到其模板范围的限制。3....
2026-01-07
【论文阅读】【ESEC\FSE 22'】Alpharepair:少训练多做事-通过零样本学习重新审视自动程序修复
论文信息 标题:Less Training, More Repairing Please: Revisiting Automated Program Repair via Zero-shot...
2025-12-29
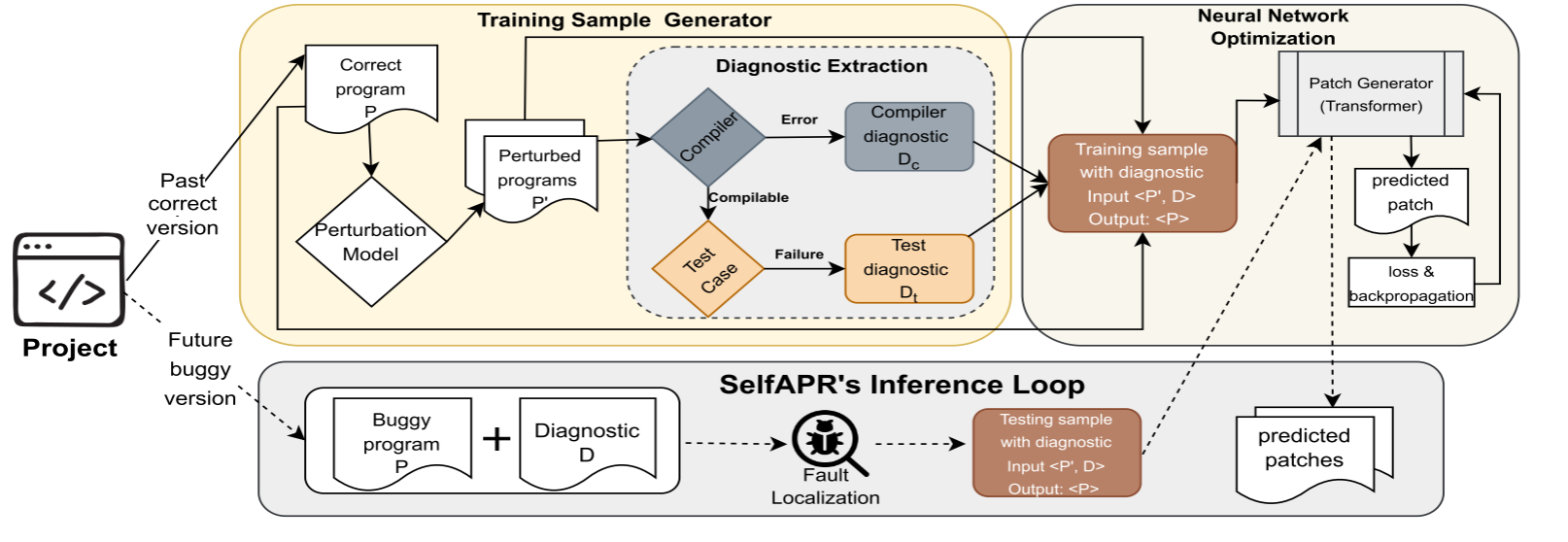
【论文阅读】【ASE 22'】SELFAPR:带有测试执行诊断的自监督APR
论文信息 题目:SelfAPR: Self-supervised Program Repair with Test Execution...
2025-10-19
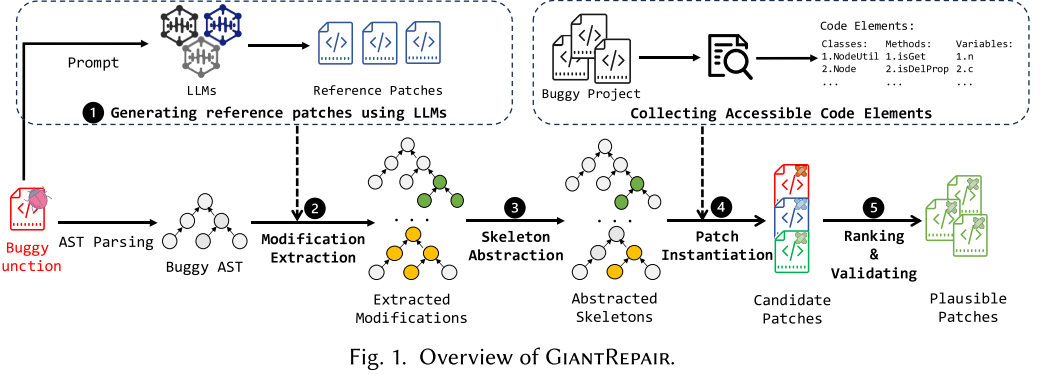
【论文阅读】【ToSEM 25'】Giant Repair:结合大型语言模型和程序分析的混合自动程序修复
论文信息题目:Hybrid Automated Program Repair by Combining Large Language Models and Program Analysis链接:Tosem 主要问题文章提出,现有的基于预定义修复模板、启发式规则和约束求解的自动程序方法难以充分利用实际应用中各种补丁的大搜索空间。其局限性在于: 基于LLM的APR方法直接利用生成补丁,没有进一步的优化。LLM通常难以生成一些有关于特定程序元素的修复方案,比如局部变量和特定域方法调用等。如何利用这些不完善的修复方案来提高整体修复能力也是一个待探索的领域。 迄今为止,APR方法评估是在漏洞已被定位的前提下进行的。这种场景并不现实。本文章的主要贡献在于: 提出GiantRepair,利用LLM输出的“并非完全正确”的补丁,从其中提取补丁骨架进行整体方法的优化; 在两种应用场景下进行优化评价; 开源:...
2025-10-14
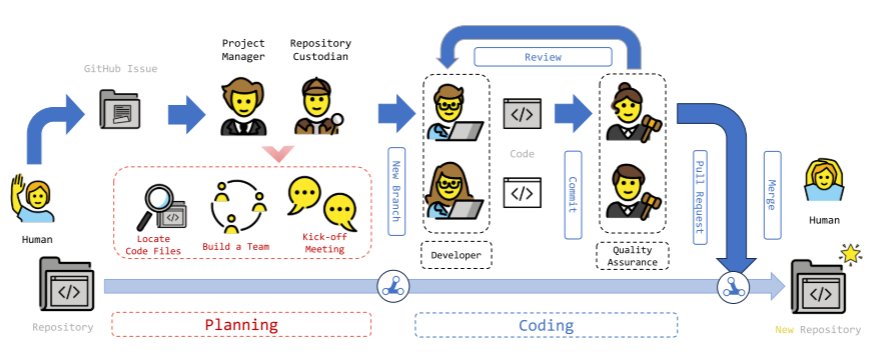
【论文阅读】【NeurIPS 24'】MAGIS:多智能体支撑的大语言模型Github问题解决——通过精心设计的智能体协作来增强问题解决能力
论文信息: 题目:MAGIS: LLM-Based Multi-Agent Framework for GitHub Issue ReSolution 链接:NeurIPS 24’ 主要问题类似Github的代码托管平台,其项目通常不是一成不变的,开源软件作者会更新多个版本,并将源码按照版本号推至代码仓,本文的根本目的是解决开源代码产生的各类“issue”,同时研究了多智能体应用对该下游任务的优化性能。本文的主要贡献如下: 我们对llm解决GitHub问题进行了实证分析,探讨了定位代码文件/行、代码变更的复杂性与解决成功率之间的相关性。 我们提出了一种新的基于llm的多智能体框架MAGIS,以减轻现有llm在GitHub问题解决上的局限性。我们设计的四类代理及其在规划和编码方面的协作都释放了llm在存储库级别编码任务上的潜力。 我们在SWE-bench数据集上比较了我们的框架和其他强大的大语言模型竞争对手(即GPT-3.5,...
评论



