【论文阅读】【ESEC\FSE 22'】Alpharepair:少训练多做事-通过零样本学习重新审视自动程序修复
论文信息
- 标题:Less Training, More Repairing Please: Revisiting Automated Program Repair via Zero-shot Learning
- 连接:https://arxiv.org/pdf/2207.08281
解决问题
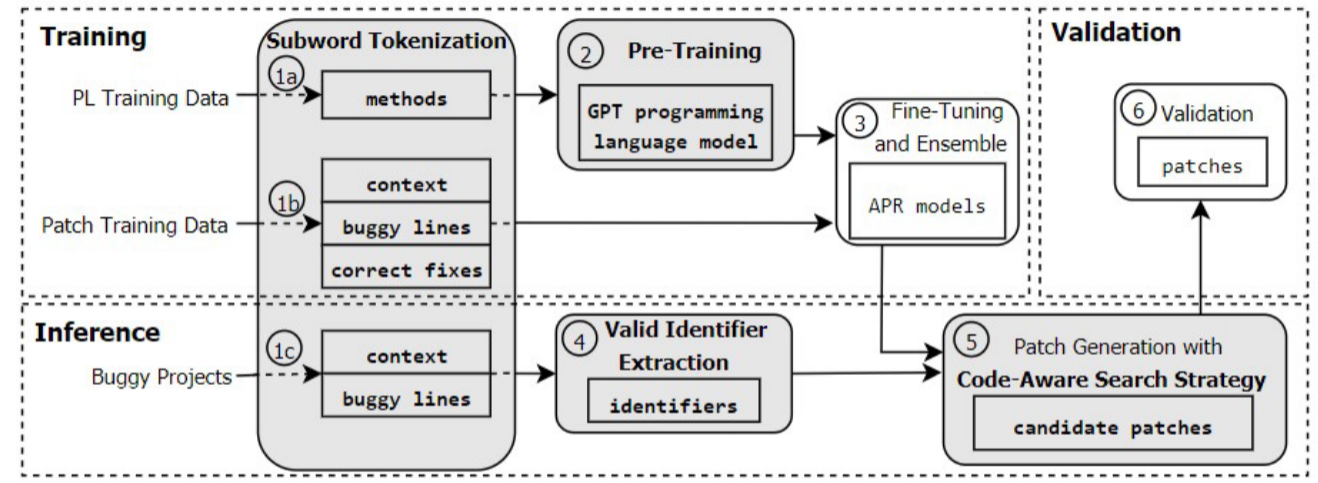
现有基于ML的APR方法具有以下局限:
- 训练数据质量。为了找到修复bug的提交,通常要用关键词过滤,这些结果中不一定包含目标修复。
- 训练数据的数量。与大量的开放源代码片段相比,bug修复的数量是有限的。为了减少上述提交包含错误修复的不相关更改的问题的影响,基于学习的APR工具通常将其数据集中的提交限制为更改较少的行。
- 上下文表示。为了对有bug的代码片段提供正确的修复,前后的上下文对于提供有用的语法/语义信息至关重要。当前基于学习的APR工具首先将包含有bug的代码元素的上下文作为纯文本或结构化表示传递给编码器。然后直接使用编码的上下文或与有缺陷的代码片段的单独编码相结合,作为解码器的输入。然而,这个过程是不自然的,因为模型很难区分上下文中的补丁位置,或者有效地合并单独的错误/上下文编码。因此,这种技术可能会忽略补丁与其上下文之间的复杂关系,例如提供重要语法/语义信息的每个代码元素的接近程度。
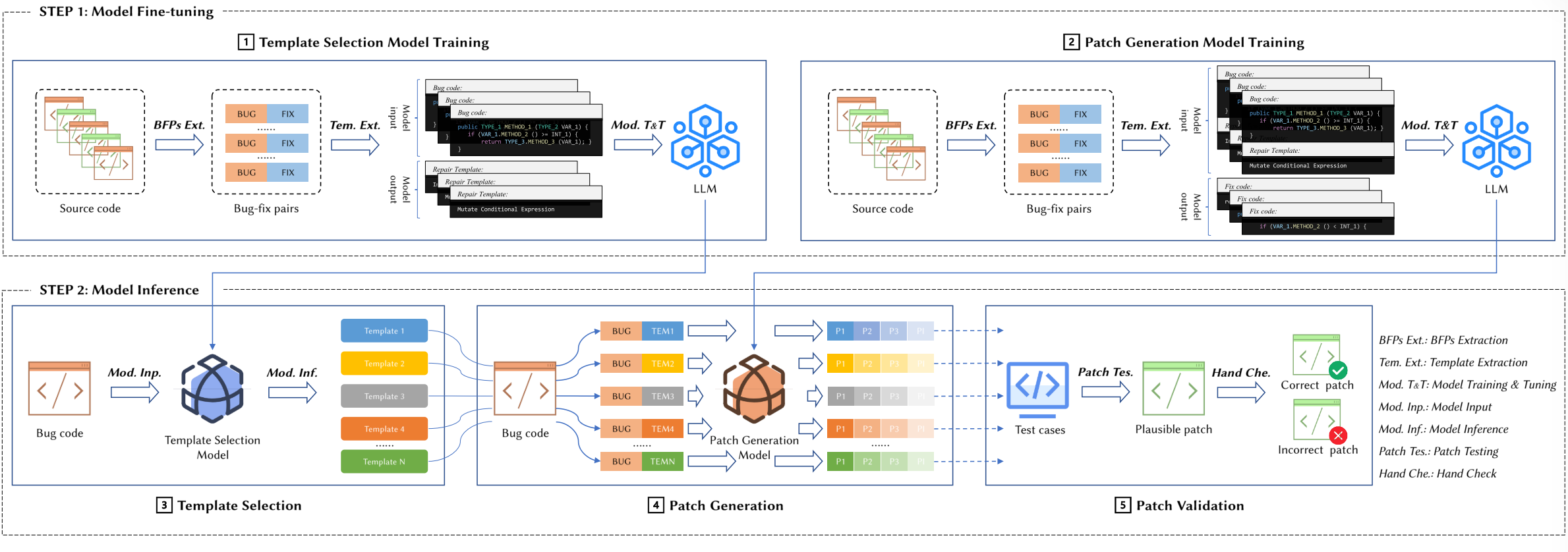
AlphaRepair是一种完形填空式的APR方法,在0样本下使用大型预训练代码模型来直接生成补丁,即无需对错误修复数据集进行任何额外的训练或微调。与所有现有的基于学习的APR技术不同,我们的主要见解是,我们可以根据上下文信息直接建模/预测正确的代码,而不是建模修复编辑应该是什么样子。通过这种方式,我们的封闭型APR可以避免现有技术的上述所有限制。
AlphaRepair
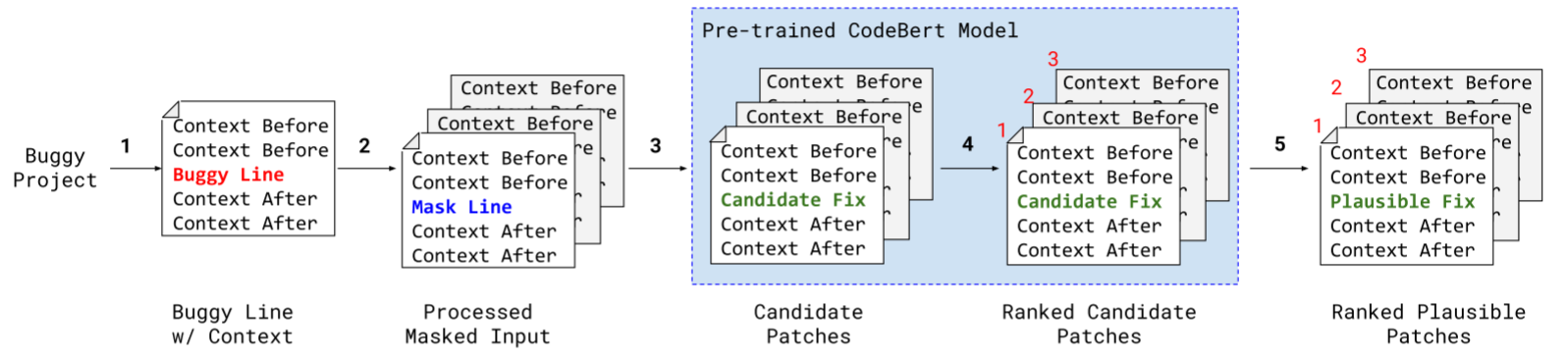
简单来说,就是覆盖掉问题部分,然后直接向CodeBERT查询填入内容,专注于单线补丁。概括为五步:
第一步:输入处理
使用使用字节级字节对编码(BBPE,通过将不常见的长词分解为语料库中常见的子词来减小词汇表大小)构建的CodeBERT标记器,下图提供了一个错误程序的示例输入。我们首先定义记号结构,一个记号列表作为CodeBERT的输入。我们对前后的上下文都进行了标记,并将掩码行夹在它们之间。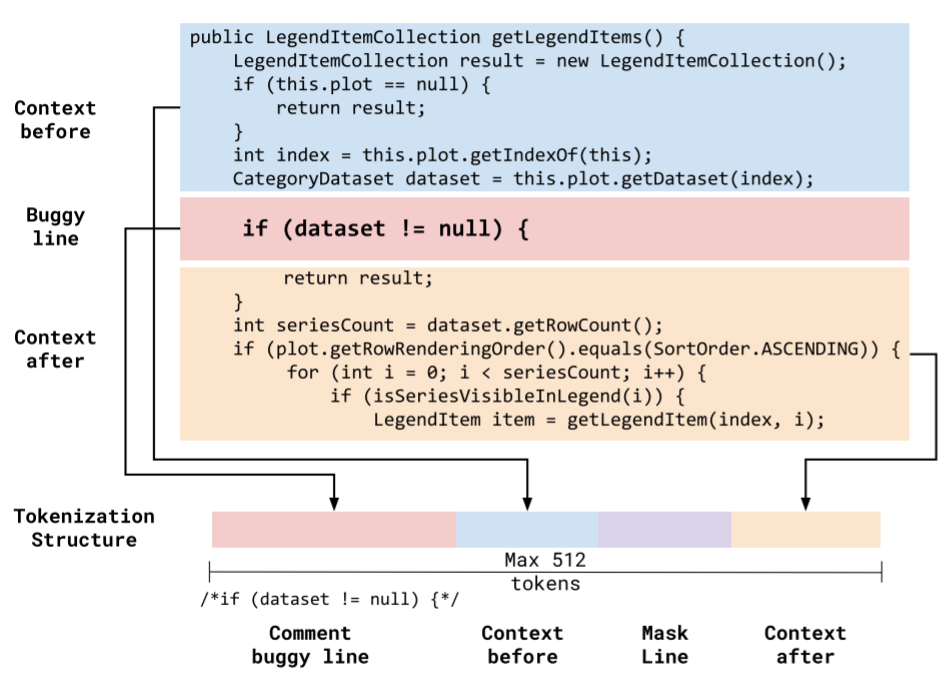
为了捕获有bug行的编码,我们利用CodeBERT的双峰特性,它可以接受编程语言和自然语言(注释)。用块注释字符将原来的有bug的行转换为注释。原有的MLM损失函数将包含函数代码和注释的两种token作为原始表示。为了最大化我们可以编码的上下文,我们从有bug的行开始,并增加上下文大小(远离有bug的代码的行),直到我们达到最大CodeBERT输入令牌大小512。
第二部:掩码生成

三种掩码策略:
- 完全掩码
最简单的策略是将整个有bug的行替换为只包含掩码标记的行。我们将此称为行替换,因为我们要求CodeBERT生成新行来替换有bug的行。我们还生成掩码行,在有bug的行之前/之后添加掩码令牌。这些表示在有bug的位置之前/之后插入新一行的bug修复。 - 部分掩码
重用来自有bug行的部分代码。我们首先将有bug的行分隔成单独的令牌,然后保留最后一个/第一个令牌,并用掩码令牌替换之前/之后的所有其他令牌。然后我们重复这个过程,但是从原始的有bug的行中添加更多的令牌来生成部分掩码行的所有可能版本。 - 模板掩码
我们针对条件和方法调用语句实现了几种基于模板的掩码行生成策略,因为它们是两种最常见的bug模式。与前两种策略不同,模板掩码只能为特定的错误行生成。第一组模板是针对有bug的方法调用设计的。方法替换将用掩码令牌替换方法调用名。这表示要求CodeBERT使用与之前相同的参数生成替换方法调用。我们还使用了几个基于参数的更改:用掩码令牌替换整个输入,用掩码令牌替换一个参数,并添加额外的参数(由于我们改变掩码令牌的数量,可以添加多个参数,因此CodeBERT可以添加多个参数)。我们还为布尔表达式形式的条件语句设计了模板掩码行。我们生成的掩码行可以替换整个布尔表达式,或者通过在语句后面添加掩码令牌来添加额外的和/或表达式。此外,我们还识别了常见的操作符(<,>,>=,==,&&,||等),并在有bug的行中直接用掩码令牌替换它们。
第三步:补丁生成
为了生成替换原始错误代码的补丁,我们使用CodeBERT为输入中的每个掩码令牌生成代码令牌。为此,我们利用CodeBERT中使用的掩膜替换的原始训练目标。CodeBERT是通过预测正确的令牌值来训练的,该令牌已被给定其周围上下文的掩码令牌替换。对于每个掩码令牌,CodeBERT输出其词汇表中每个令牌的概率,以替换掩码令牌。通常,在训练期间,一小部分令牌被屏蔽(< 15%),模型将尝试预测已被替换的实际令牌。
我们的任务类似于CodeBERT的原始训练目标,我们也对输入进行了预处理,使一小组令牌被屏蔽掉。然而,我们的输入和掩码训练数据之间的一个关键区别是我们的掩码令牌被分组在一起。要为中间的掩码令牌生成输出,之前/之后的直接上下文都是掩码令牌。为了便于为分组掩码令牌生成令牌,我们通过用先前生成的令牌替换掩码令牌来迭代输出令牌。如下:
第四步:补丁排序
重新排序过程再次使用CodeBERT模型。关键思想是在每个补丁完全生成后为其提供一个准确的分数(即可能性),以获得更有效的补丁排名。我们从包含所有生成的令牌的完整补丁开始。然后,我们只屏蔽其中一个令牌并查询CodeBERT以获得该令牌的条件概率。我们对所有其他先前的掩码令牌位置应用相同的过程,并计算联合分数,这是单个令牌概率的平均值。联合得分现在可以被理解为生成序列的条件概率(即给定前后两种上下文,根据CodeBERT生成补丁的可能性是多少?)这对所有掩码生成策略(完整、部分和模板掩码)生成的所有补丁都是如此。
第五步:补丁验证
对于我们生成的每个候选补丁,我们对有bug的文件应用相应的更改。我们编译每个补丁并过滤掉任何无法编译的补丁。然后,我们针对每个编译的补丁运行测试套件,以找到通过所有测试的可信补丁。
实验
RQ1对比

显示了AlphaRepair以及其他同样使用完美故障定位的基线的性能。AlphaRepair可以成功地为74个错误生成正确的修复程序,优于所有以前的基线,包括传统的和基于学习的APR技术。
韦恩图估了只有AlphaRepair才能修复的独特错误的数量。
RQ2消融

研究添加不同组件对AlphaRepair设计的贡献,上表包含了结果,每一行代表一个组件,以及AlphaRepair可以产生的正确/可信补丁数量的增加。