

【待焚稿】两篇在qq空间发过的癫
题目与林黛玉没有任何关系,纯属本人瞎编。曾经瞎写的东西,在这里做个备份。 蜘蛛 我原本以为它再也不会回来了,但是它还是回来了。 五天前一次不经意的抬头,我发现了这只蜘蛛。它在大寝衣架和窗台间缝隙处织了一张和它体积不成比例的巨大的网,我发现它时它就这样静静地挂在网的正中心,一动也不动。我轻轻地一吹气,它立刻收起八条腿,缩成球;我猛地吹一大口起,它便以极快的速度,极其敏捷的动作撤回阴影里面。后来的一次集体大扫除似乎打扰了它平静的生活,也戳破了它的杰作,它便消失了,只剩下一张支离破碎的网。我以为它一定是去寻找更加适合安家的地方,重新织一张网继续自己无聊枯燥的生活了。 我想起了最近在读的那本书,阎真老师的《沧浪之水》,主人公池大为在官场里面的浮沉是故事的核心。年轻时的池大为就像所有血气方刚的年轻人一样,满腔热血,充满正义感,心向往着像屈原、陶渊明那样历史浪潮中那些代表着清廉正直,不随波逐流的清高形象。但当他有了自己的家庭后,他渐渐发现,他的清高正在将他推向万丈深渊,让他的妻子和孩子跟着他一起受排挤,有什么好处都被别人揽了去…于是,他逐渐放下自己曾经奉为圭臬的人生原则...
【论文阅读】CLIP4Clip:端到端视频检索的CLIP实证研究
论文信息:Luo H , Ji L , Zhong M ,et al.CLIP4Clip: An Empirical Study of CLIP for End to End Video Clip Retrieval[J]. 2021.DOI:10.48550/arXiv.2104.08860. 源码: https://github.com/ArrowLuo/CLIP4Clip. 试验方案:https://github.com/towhee-io/examples/blob/main/video/text_video_retrieval/1_text_video_retrieval_engine.ipynb 文章概述 先说下CLIP:CLIP全称Constrastive Language-Image...
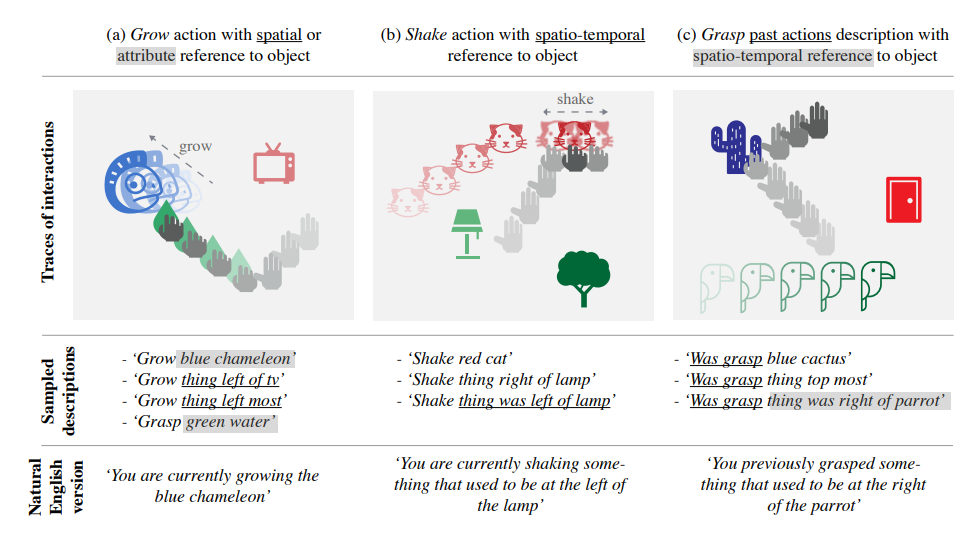
【论文阅读】Grounding Spatio-Temporal Language with Transformers
文章信息:Karch T , Teodorescu L , Hofmann K ,et al.Grounding Spatio-Temporal Language with Transformers[J]....

【论文阅读】TALL:通过自然语言定位时间活动
论文信息:Gao J , Sun C , Yang Z ,et al.TALL: Temporal Activity Localization via Language Query[J].arXiv e-prints, 2017.DOI:10.1109/iccv.2017.563. 代码:https://github.com/WuJie1010/Awesome-Temporally-Language-Grounding 1实现自然语言定位活动的挑战有以下几个方面:1)符合需求的多模态(语言查询和动作定位)表现;2)根据细度有限的特征准确地完成任务。我们提出了一种跨模态的时间回归定位器来联合两种模型,输出指定视频片段的对齐分数和动作边界回归结果。 传统的定位方法多使用基于光学流或者卷积神经网络训练的分类器,并且以滑动窗口的方式实现。一种支持自然语言查询的直接实现方式是吧查询分为离散的标签集合,然而要设计一种能够照顾大范围活动且不会丢失用户查询中的重要信息的标签集合并不容易。 为了能够解决离散活动标签的问题,一种可能的办法是将可视特征和句意特征都嵌入一个空间(common...

【论文阅读】基于深度学习的键盘声学侧信道攻击
论文信息:Harrison, Joshua J. et al. “A Practical Deep Learning-Based Acoustic Side Channel Attack on Keyboards.” 2023 IEEE European Symposium on Security and Privacy Workshops (EuroS&PW) (2023): 270-280. 背景侧信道攻击(SCA,Side Channel...
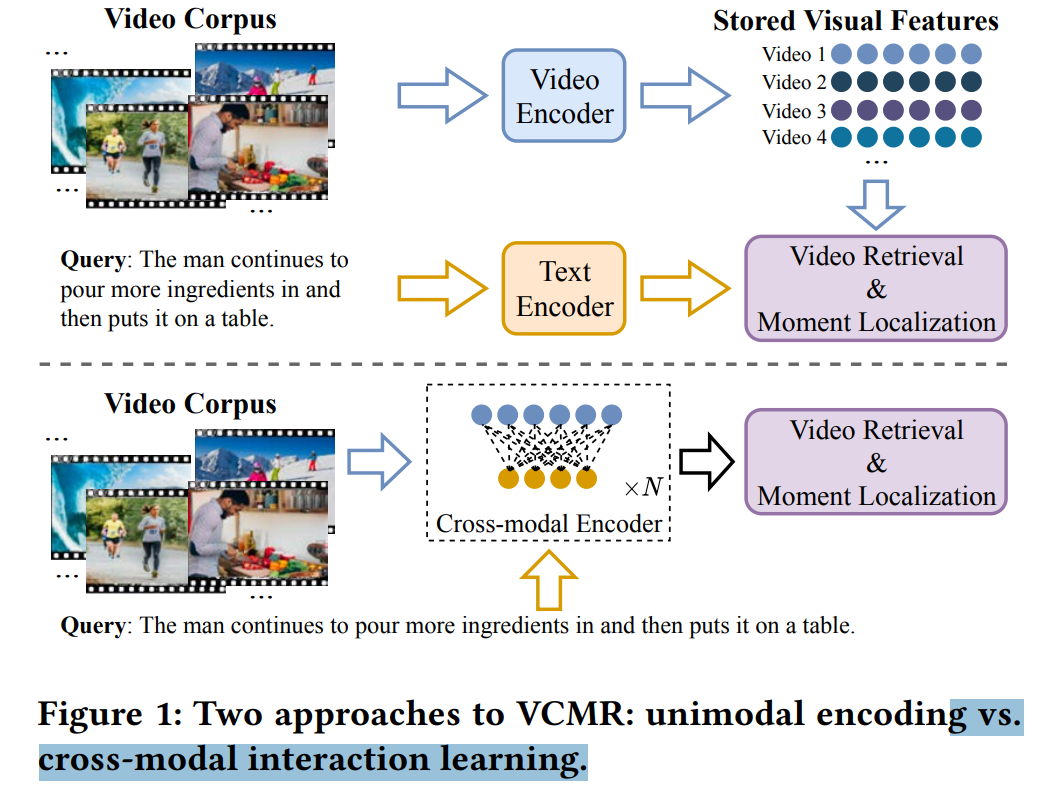
【论文阅读】基于对比学习的视频片段检索
论文信息:Zhang, Hao et al. “Video Corpus Moment Retrieval with Contrastive Learning.” Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval (2021): n. pag. 摘要+引言部分 视频语料库片段检索(Video Corpus Moment Retrieval,VCMR)的目的是通过给定查询语句的语义查找对应的视频时域片段。由于视频和文本信息来自两个不同的特征空间,如何实现VCMR有两种基本方式:(i)独立加码每个模型的输出,然后将两个模型输出按顺序执行(原文表述为align,在前几篇论文中则表述为前一模型的输出为后一模型的输入)、(ii)使用细粒度跨模态交互。在本文提出的ReLoCLNet(Retrieval and Localization Network with Contrastive...

【打靶】AdmX_new
靶机地址:https://download.vulnhub.com/admx/AdmX_new.7z 信息搜集及主机发现主机发现nmap -sn 192.168.40.0/24 netdiscover -r 192.168.40.0/24 这里再记录一工具arping,相较于arp-scan它范围更广,配合简单的bash使用。 for i in $(seq 1 256);do sudo arping -c 1 192.168.40.$i;done kali:192.168.40.148 靶机:192.168.40.150 信息搜集靶机端口、服务、操作系统探测nmap -sV -p- -O 192.168.40.150 主机只开放了80端口,访问后为apache的默认配置界面。 目录爆破dirsearch -u 192.168.40.150:80 80端口下存在/wordpress...

【论文阅读】mTVL:支持多语言的视频片段检索
论文原标题: Lei J , Berg T L , Bansal M .MTVR: Multilingual Moment Retrieval in Videos[J]. 2021.DOI:10.48550/arXiv.2108.00061. 源码:https://github.com/jayleicn/mTVRetrieval 摘要及引言:采用数据集MTVR:一种在TVR数据集的基础上增加了相应的中文查询和标题,包含了对21.8K条视频的218K条英语和中文的查询,是最大的视频检索数据集,且支持对话检索(以字幕的形式)。 提出了mXML:一个支持双语言的多片段检索模型,它通过参数共享和限制语言邻域在数据集上执行操作和训练。在XML(by Lei,2020)的基础上加入了参数共享(by Sachan and Neubig,2018;Dong,2015)使得两个语言可以用统一的解码器解码。引入语言邻域限制(by...

【打靶】Socnet
靶机下载地址:https://download.vulnhub.com/boredhackerblog/medium_socnet.ova 主机探测arp-scan -l nmap -sn 192.168.40.0/16 kali:192.168.40.148 靶机:192.168.40.149 开始时没能使用工具扫描到靶机ip,最后才发现是因为VMware默认采用了桥接模式而非NAT模式将其接入网络。 进一步信息收集1.端口、服务、操作系统探测nmap -sV -sC -O 192.168.40.149 目标开放了22、5000端口,在5000端口运行了一个由python2编写的http服务“Werkzeug”。在按照提示输入少于4字符长度的信息时会提示输入不够长 2.目录扫描dirsearch -u 192.168.40.149:5000 对5000端口进行目录扫描,发现一个/admin目录,访问,内有一个可执行python代码的入口。 尝试利用1.利用python来反弹shell先在kali监听5555端口: nc -lvnp...
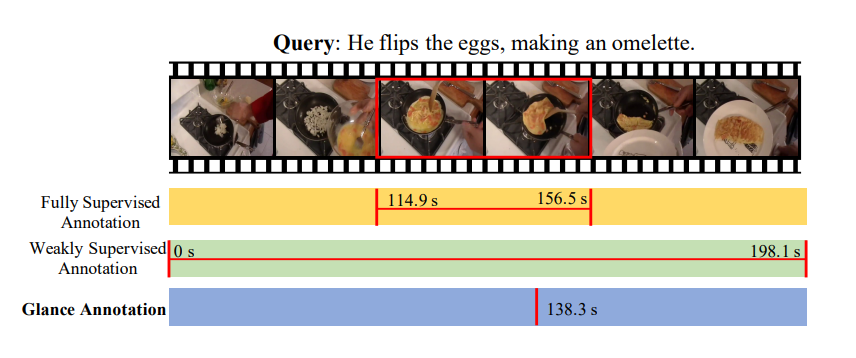
【论文阅读】基于跨模型交互网络的视频片段检索
文章信息:Zhang Z , Lin Z , Zhao Z ,et al.Cross-Modal Interaction Networks for Query-Based Moment Retrieval in Videos[J].ACM, 2019.DOI:10.1145/3331184.3331235. 源码: https://github.com/ikuinen/CMIN 引言部分对标题【跨模型】的解释要从一个连续的复杂的视频中定位出一小段特定的片段要比从已定义的集和中找出一个视频要困难的多。在下图所示的例子中,一个句子包含了两个连续的动作,对应了视频中的两段内容。因此正确的视频内容检索需要理解视频以及查询内容,二者缺一不可。这点就需要跨模形(cross-modal)的支持。 本文对高质量视频检索的考虑首先查询内容通常包含了因果时间上的行为,因此学习细粒度查询表示就很重要。目前的方法使用循环神经网络(如GRU)来理解查询语句语义,但它们通常无法顾及句法结构。 本文所采用的是图卷积网络(GCN,Graph convolution...




